Build your Backend with Netlify Functions in 20 minutes
Netlify makes deploying your front end quick and easy, and Netlify functions makes running a serverless backend just as easy.
In this guide, we'll get setup on how to use Netlify functions. As an indie developer, you should embrace serverless offerings because of their low barrier to entry and generous free tiers. And as an enterprise shop, you should seriously consider them for an extremely cheap, fast, and scalable way to build out your backend infrastructure.
Use Cases - What can you build?
Modern JavaScript frameworks allow us to build large and complex applications on the client, but they can occasionally run into limitations. For everything else, there's the "backend" which excels at handling some of these use cases:
- Protecting Secrets & Credentials
- Server Side Rendering
- Sending Emails
- Handling File IO
- Running centralized logic
- Executing tasks off the main thread
- Bypassing CORS issues for locked down APIs
- Providing Progressive Enhancement / NoScript Fallback
Composition of a Function
Netlify Functions provides a wrapper around AWS Lambdas. While the Netlify documentation should be sufficient, it's good to know that there's an escape hatch if you ever want to run on your own AWS subscription. However, Netlify handles some of the deployment magic for you, so let's start there.
Here's the bare bones of a Netlify function in JavaScript:
exports.handler = async function(event, context) {
return {
statusCode: 200,
body: JSON.stringify({message: "Hello World"})
};
}
If you're familiar with running JavaScript on Node, this should look somewhat familiar. Each function should live in its own file, and will execute whatever is assigned to exports.handler. We have access to event and context. We can run whatever code we need on Node, and return whatever response type we'd like.
To set this up, lets create an empty repository on GitHub. We need to add functions to a folder. While we can use any name, a common pattern is to create a folder name functions. Let's add a file in there called hello.js
//functions/hello.js
exports.handler = async (event, context) => {
const { name = "Anonymous" } = event.queryStringParameters;
return {
statusCode: 200,
body: `Hello, ${name}`
};
};
In our function, we can grab information from the query string parameters passed in. We'll destructure those (with a default value) and look for a name param.
To actually wire up our functions folder, we'll need to add a netlify.toml config file at the root of our project.
# netlify.toml
[build]
functions = "functions/"
Walk Before You Run (Locally)
Our "repo" should look like this at this point:
my-app
├── functions
│ └── hello.js
└── netlify.toml
The best way to run your Netlify site locally, with all the bells and whistles attached, is to use Netlify Dev which you can install via npm:
npm install netlify-cli -g
And then kick off your dev server like this:
netlify dev
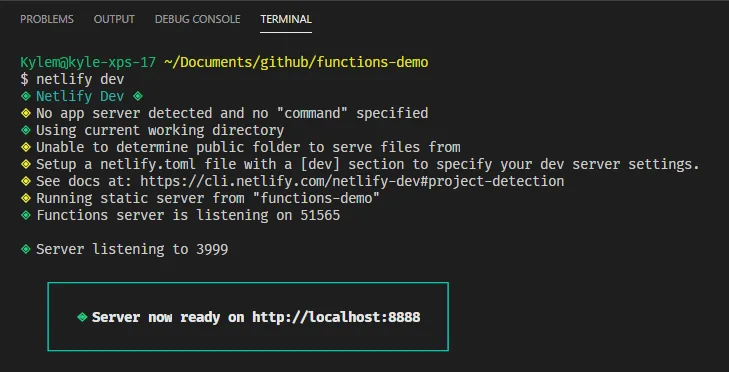
Your "site" should now be live at http://localhost:8888. By default, Netlify hosts functions under the subpath /.netlify/functions/<fn-name> so you can invoke your function here:
http://localhost:8888/.netlify/functions/hello?name=Beth
Now, let's make our function's address a little cleaner by also taking advantage of another free Netlify feature using redirects. This allows us to expose the same functions at a terser url by replacing /.netlify/functions with /api.
FROM: <site>/.netlify/functions/hello
TO: <site>/api/hello
To do so, append the following info to your netlify.toml config, and restart Netlify dev:
[[redirects]]
from = '/api/*'
to = '/.netlify/functions/:splat'
status = 200
This will route all traffic at /api/* internally to the appropriate functions directory, and the wildcard will capture all additional path info, and move to :splat. By setting the HTTP Status Code = 200, Netlify will preform a "rewrite" (as opposed to a "redirect") which will change the server response without changing the URL in the browser address bar.
So let's try again with our new url:
http://localhost:8888/api/hello?name=Beth
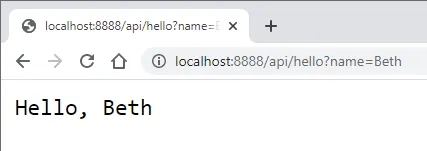
👏 Awesome, you just created a function! (you're following along live, right?)
Getting the CRUD Out & Submitting Data
Now that we can build functions, let's create our own API with some basic CRUD functions (Create, Read, Update, & Delete) for a simple todos app.
One of the central tenants of serverless computing is that it's also stateless. If you need to store any state across function invocations, it should be persisted to another, layer like a database. For this article, let's use the free tier of DynamoDb, but feel free to BYODB (Bring Your Own DB), especially if it has a Node SDK.
In the next steps, we'll:
- Setup a table on DynamoDB in AWS
- Install npm packages into our project
- Setup secret keys in AWS, and add to our environment variables
- Initialize the aws-sdk package for NodeJs
- And then finally add a Netlify function route to create a record on our database
AWS - Amazon Web Services
This guide will assume some degree of familiarity with AWS & DynamoDB, but if you're new to DynamoDB, you can start with this guide on Getting Started with Node.js and DynamoDB.
On AWS, create a table with the name NetlifyTodos, and string partition key called key.
NPM - Node Package Manager
Now, let's setup npm and install aws-sdk, nanoid, & dotenv.
In a terminal at the root of your project, run the following commands:
npm init -y
npm install aws-sdk nanoid dotenv --save
ENV - Environment Variables
You'll need to provision an access key / secret for an IAM user that we'll use to authenticate our API calls. One of the benefits of running these calls on the server is you're able to protect your application secret through environment variables, instead of having to ship them to the client, which is not recommended.
There are quite a few ways to log into AWS on your local machine, but just to keep everything inside of our project, let's create a .env file at the root of our project, and fill in the following keys with your own values:
# .env
MY_AWS_ACCESS_KEY_ID=***
MY_AWS_SECRET_ACCESS_KEY=***
MY_AWS_REGION=us-east-1
NOTE: One little gotcha here is that the more common AWS_ACCESS_KEY_ID is a reserved environment keyword used by the Netlify process. So if we want to pass around env variables, we'll have to use our own key, in this case prefixed with MY_.
Once they're added to the process, we can destructure them and use in setting up our AWS SDK. We'll need to setup AWS for every CRUD function, so let's assemble all this logic in a separate file called dyno-client.js.
// dyno-client.js
require('dotenv').config()
const { MY_AWS_ACCESS_KEY_ID, MY_AWS_SECRET_ACCESS_KEY, MY_AWS_REGION } = process.env
The following is required.
SDK - Software Developer Kit
Using the aws-sdk makes our life a lot easier for connecting to DynamoDB from our codebase. We can create an instance of the Dynamo client that we'll use for the remaining examples:
// dyno-client.js
const AWS = require("aws-sdk");
AWS.config.update({
credentials: {
accessKeyId: MY_AWS_ACCESS_KEY_ID,
secretAccessKey: MY_AWS_SECRET_ACCESS_KEY
},
region: MY_AWS_REGION,
});
const dynamoDb = new AWS.DynamoDB.DocumentClient();
To make this available to all our functions, add the DynamoDB instance to your exports, and we'll grab it when we need it:
module.exports = { dynamoDb, TABLE_NAME }
Create Todo (Due by EOD 😂)
⚡ We're finally ready to create our API function!
In the following example, we'll post back form data containing the text for our todo item. We can parse the form data into JSON, and transform it into an item to insert into our table. If it succeeds, we'll return the result with a status code of 200, and if it fails, we'll return the the error message along with the status code from the error itself.
// functions/create.js
const { nanoid } = require("nanoid");
const { dynamoDb } = require("../dyno-client")
exports.handler = async(event, context) => {
try {
// parse form data
const body = JSON.parse(event.body);
// create item to insert
const params = {
TableName: TABLE_NAME,
Item: {
key: nanoid(7),
text: body.text,
createDate: new Date().toISOString(),
},
};
let result = await dynamoDb.put(params).promise();
// return success
return {
statusCode: 200,
body: JSON.stringify({
success: true,
data: result,
}),
};
} catch (error) {
return {
statusCode: error.statusCode || 500,
body: JSON.stringify(error),
};
}
};
This should give you the gist of how to expose your API routes and logic to perform various operations. I'll hold off on more examples because most of the code here is actually just specific to DynamoDB, and we'll save that for a separate article. But the takeaway is that we're able to return something meaningful with very minimal plumbing. And that's the whole point!
With Functions, you only have to write your own business logic!
Debugging - For Frictionless Feedback Loops
There are two critical debugging tools in Visual Studio Code I like to use when working with node and API routes.
- Script Debugger &
- Rest Client Plugin
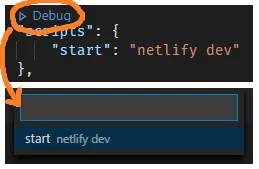
✨ Did you know, instead of configuring a custom launch.json file, you can run and attach debuggers directly onto npm scripts in the package.json file:
And while tools like Postman are a valuable part of comprehensive test suite, you can add the REST Client Extension to invoke API commands directly within VS Code. We can easily use the browser to mock GET endpoints, but this makes it really easy to invoke other HTTP verbs, and post back form data.
Just add a file like test.http to your project. REST Client supports expansion of variable environment, and custom variables. If you stub out multiple calls, you can separate multiple different calls by delimiting with ###.
Add the following to your sample file:
@baseUrl = http://localhost:8888
// create todo item
POST {{baseUrl}}/api/create
content-type: application/json
{
"text": "Feed the cats",
}
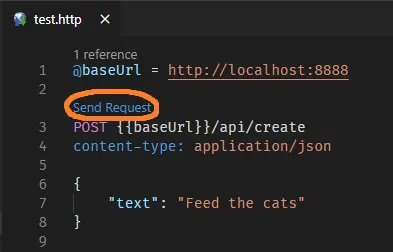
We can now run the above by clicking "Send Request". This should hit our Netlify dev server, and allow us to step through our function logic locally!
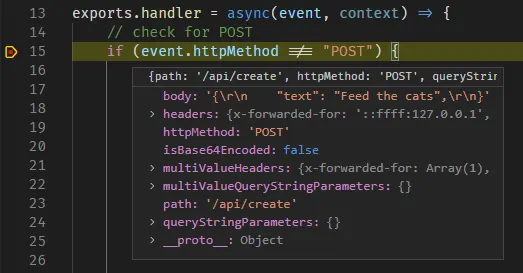
Publishing
Publishing to Netlify is easy as well. Make sure your project is committed, and pushed up to a git repository on GitHub, GitLab or BitBucket.
Login to Netlify, and click the option to Create "New Site From Git" and select your repo.
Netlify will prompt for a Build command, and a Publish directory. Believe it or not, we don't actually have either of those things yet, and it's probably a project for another day to set up our front end. Those commands refer to the static site build part of the deployment. Everything we need to build serverless functions is inside our functions directory and our netlify.toml config.
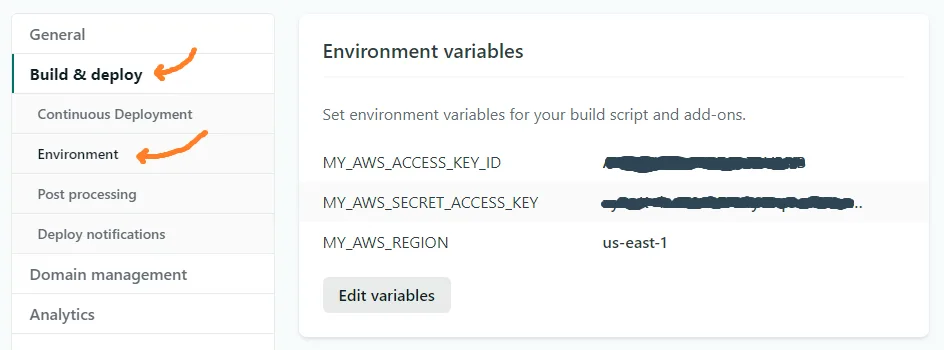
Once we deploy the site, the last thing we'll need to do is add our environment variables to Netlify under Build > Environment
Next Steps - This is only the beginning
Hopefully some ideas are spinning as to how you can use these technologies on your own sites and projects. The focus of this article is on building and debugging Netlify functions, but an important exercise left to the reader is to take advantage of that on your front end.
TIP: If you want to add Create React App to your current directory (without creating a new folder), add a . when scaffolding out a new app like this:
create-react-app .
Try it out - build a front end, and let me know how it goes at KyleMitBTV!
For more context, you can browse the full source code for the article on GitHub at KyleMit/netlify-functions-demo.
For even more practical examples with actual code, checkout the following resources as well!
- David Wells - Netlify Serverless Functions Workshop
- netlify/functions - Community Functions Examples
Good luck, and go build things!




