When working with relational data, there will be times when you will need to access information within nested queries. But how would this work within the context of Apollo Server?
In this article, we will take a look at a few code examples that explore different solutions on how to resolve nested queries in Apollo Server. I have included all code examples in CodeSandbox if you are interested in trying them out on your own.
Prerequisites
This article assumes that you have a basic knowledge of GraphQL terminology.
Table of Contents
- How to resolve nested queries: An approach using resolvers and the filter method
- A refactored approach using Data Loaders and Data Sources
- Resolving nested queries when microservices are involved
- Conclusion
How to resolve nested queries: An approach using resolvers and the filter method
In this first example, we are going to be working with two data structures called musicBrands and musicAccessories. musicBrands is a collection of entities consisting of id and name. musicAccessories is a collection of entities consisting of the product name, price, id and an associated brandId. You can think of the brandId as a foreign key that connects the two database tables.
We also need to set up the schemas for the brands and accessories.
const typeDefs = gql`
scalar USCurrency
type MusicBrand {
id: ID!
brandName: String
}
type MusicAccessories {
id: ID!
product: String
price: USCurrency
brandId: Int
brand: MusicBrand
}
type Query {
accessories: [MusicAccessories]
}
`;
The next step is to set up a resolver for our Query to return all of the music accessories.
const resolvers = {
Query: {
accessories: () => musicAccessories,
},
};
When we run the following query and start the server, we will see this JSON output:
query Query {
accessories {
product
brand {
brandName
}
}
}
{
"data": {
"accessories": [
{
"product": "NS Micro Violin Tuner Standard",
"brands": null
},
{
"product": "Standard Gong Stand",
"brands": null
},
{
"product": "Black Cymbal Mallets",
"brands": null
},
{
"product": "Classic Series XLR Microphone Cable",
"brands": null
},
{
"product": "Folding 5-Guitar Stand Standard",
"brands": null
},
{
"product": "Black Deluxe Drum Rug",
"brands": null
}
]
}
}
As you can see, we are getting back the value of null for the brands field. This is because we haven't set up that relationship yet in the resolvers.
Inside our resolver, we are going to create another query for the MusicAccessories and have the value for the brands key be a filtered array of results for each brand.
const resolvers = {
Query: {
accessories: () => musicAccessories,
},
MusicAccessories: {
// parent represents each music accessory
brand: (parent) => {
const isBrandInAccessory = (brand) => brand.id === parent.brandId;
return musicBrands.find(isBrandInAccessory);
},
},
};
When we run the query, this will be the final result:
query Query {
accessories {
product
brand {
brandName
}
}
}
{
"data": {
"accessories": [
{
"product": "NS Micro Violin Tuner Standard",
"brands": [
{
"brandName": "D'Addario"
}
]
},
{
"product": "Standard Gong Stand",
"brands": [
{
"brandName": "Zildjian"
}
]
},
{
"product": "Black Cymbal Mallets",
"brands": [
{
"brandName": "Zildjian"
}
]
},
{
"product": "Classic Series XLR Microphone Cable",
"brands": [
{
"brandName": "D'Addario"
}
]
},
{
"product": "Folding 5-Guitar Stand Standard",
"brands": [
{
"brandName": "Fender"
}
]
},
{
"product": "Black Deluxe Drum Rug",
"brands": [
{
"brandName": "Zildjian"
}
]
}
]
}
}
This single query makes it easy to access the data we need on the client side as compared to the REST API approach. If this were a REST API, then we would be dealing with multiple API calls and a Promise.all which could get a little messy.
You can find the entire code in this CodeSandbox example.
A refactored approach using Data Loaders and Data Sources
Even though our first approach does solve the issue of resolving nested queries, we still have an issue fetching the same data repeatedly. Let’s look at this example query:
query MyAccessories {
accessories {
id
brand {
id
brandName
}
}
}
If we take a look at the results, we are making additional queries for the brand each time we request the information. This leads to the N+1 problem in our current implementation. We can solve this issue by using Data Loaders and Data Sources.
What are Data Loaders
Data Loaders are used to batch and cache fetch requests. This allows us to fetch the same data and work with cached results, and reduce the number of API calls we have to make.
To learn more about Data Loaders in GraphQL, please read this helpful article.
How to setup a Data Source
In this example, we will be using the following packages:
We first need to create a BrandAccessoryDataSource class which will simulate the fetching of our data.
class BrandAccessoryDataSource extends DataSource {
...
}
We will then set up a constructor with a custom Dataloader.
constructor() {
super();
this.loader = new DataLoader((ids) => {
if (!ids.length) {
return musicAccessories;
}
return musicAccessories.filter((accessory) => ids.includes(accessory.id));
});
}
Right below our constructor, we will set up the context and cache.
initialize({ context, cache } = {}) {
this.context = context;
this.cache = cache || new InMemoryLRUCache();
}
We then want to set up the error handling and cache keys for both the accessories and brands. To learn more about how caching works with GraphQL, please read through this article.
didEncounterError(error) {
throw new Error(`There was an error loading data: ${error}`);
}
cacheKey(id) {
return `music-acc-${id}`;
}
cacheBrandKey(id) {
return `brand-acc-${id}`;
}
Next, we are going to set up an asynchronous function called get which takes in an id. The goal of this function is to first check if there is anything in the cached results and if so return those cached results. Otherwise, we will set that data to the cache and return it. We will set the ttl(Time to Live in cache) value to 15 seconds.
async get(id) {
const cacheDoc = await this.cache.get(this.cacheKey(id));
if (cacheDoc) {
return JSON.parse(cacheDoc);
}
const doc = await this.loader.load(id);
this.cache.set(this.cacheKey(id), JSON.stringify(doc), { ttl: 15 });
return doc;
}
Below the get function, we will create another asynchronous function called getByBrand which takes in a brand. This function will have a similar setup to the get function but will filter out the data by brand.
async getByBrand(brand) {
const cacheDoc = await this.cache.get(this.cacheBrandKey(brand.id));
if (cacheDoc) {
return JSON.parse(cacheDoc);
}
const musicBrandAccessories = musicAccessories.filter(
(accessory) => accessory.brandId === brand.id
);
this.cache.set(
this.cacheBrandKey(brand.id),
JSON.stringify(musicBrandAccessories),
{ ttl: 15 }
);
return musicBrandAccessories;
}
Setting up our schemas and resolvers
The last part of this refactored example includes modifying the resolvers. We first need to add an accessory key to our Query schema.
type Query {
brands: [Brand]
accessory(id: Int): Accessory
}
Inside the resolver, we will add the accessories key with a value for the function that returns the data source we created earlier.
// this is the custom scalar type we added to the Accessory schema
USCurrency,
Query: {
brands: () => musicBrands,
accessory: (_, { id }, context) => context.dataSources.brandAccessories.get(id),
},
We also need to refactor our Brand resolver to include the data source we set up earlier.
Brand: {
accessories: (brand, _, context) =>
context.dataSources.brandAccessories.getByBrand(brand),
},
Lastly, we need to modify our ApolloServer object to include the BrandAccessoryDataSource.
const server = new ApolloServer({
typeDefs,
resolvers,
dataSources: () => ({ brandAccessories: new BrandAccessoryDataSource() }),
});
Here is the entire CodeSandbox example.
When the server starts up, click on the Query your server button and run the following query:
query Query {
brands {
id
brandName
accessories {
id
product
price
}
}
}
Resolving nested queries when microservices are involved
Microservices is a type of architecture that will split up your software into smaller independent services. All of these smaller services can interact with a single API data layer. In this case, this data layer would be GraphQL. The client will interact directly with this data layer, and will consume API data from a single entry point.
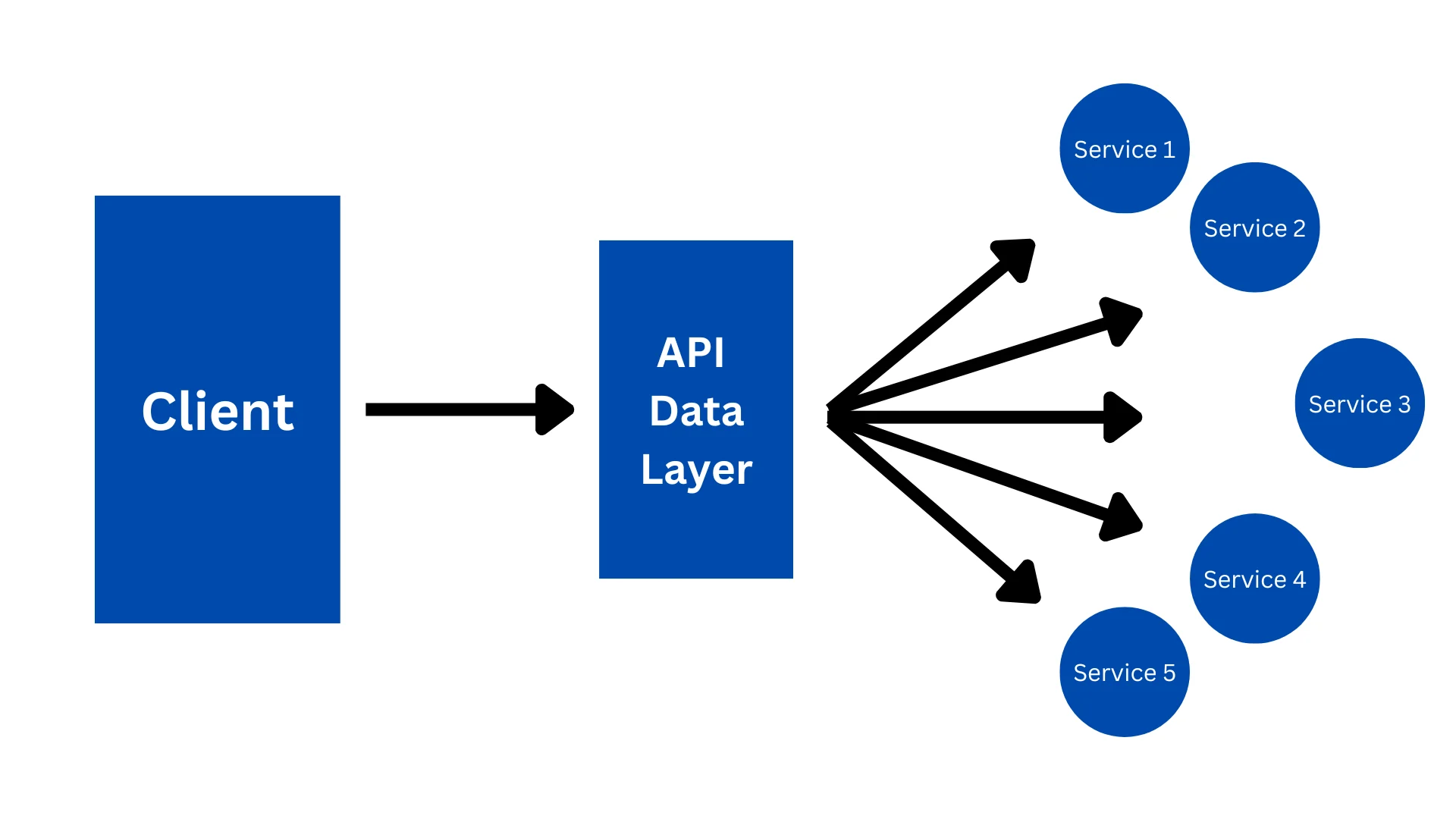
You would similarly resolve your nested queries as before because, at the end of the day, there are just functions. But now, this single API layer will reduce the number of requests made by the client because only the data layer will be called. This simplifies the data fetching experience on the client side.
Conclusion
In this article, we looked at a few code examples that explored different solutions on how to resolve nested queries in Apollo Server. The first approach involved creating custom resolvers and then using the filter method to filter out music accessories by brand. We then refactored that example to use a custom DataLoader and Data Source to fix the "N+1 problem". Lastly, we briefly touched on how to approach this solution if microservices were involved.
If you want to get started with Apollo Server and build your own nested queries and resolvers using these patterns, check out our serverless-apollo-contentful starter kit!




