
Introduction
Cypress Studio has been around for some time. It was introduced in Cypress v6.3.0, removed in v10, and reintroduced in v10.7.0. This blog post will dive into its current state and how to use it today.
What is Cypress Studio
Cypress Studio is a tool built on top of Cypress. It offers an interface for creating tests as if you were using your site without requiring code to be written. It adds functionality to query elements and to add assertions from the interface. It's important to note that Cypress Studio is still under an experimental flag and lacks support for Component Testing (another feature of Cypress).
Creating an app to test
We first need a working app because the tool we will use is meant for end-to-end tests. I'll pick Svelte and Vite for this demo, but you can choose any framework. Cypress is agnostic in that matter.
npm create vite@latest cypress-studio-svelte
Make sure to select the Svelte and Typescript options to follow along.
Now open your project location, install dependencies, and start your app to ensure everything works correctly.
cd cypress-studio-svelte
npm i
npm run dev --open

Installing and setting up Cypress Studio
Now it's time to add Cypress to our dev dependencies.
npm i -D cypress
With our dependency installed, let's launch it so we can start configuring it. But first let’s add an entry under scripts in our package.json file.
// ...
"scripts": {
// ...
"cypress": "cypress"
}
// ...
npm run cypress open
A new window will open that will guide us through the initial setup.

Select the "E2E Testing" option to create the required configuration files. Then, you can close the window.
A new folder called cypress and a configuration file cypress.config.ts are created at the root of our project.
To enable Cypress Studio, we must open the newly created configuration file and add the experimentalStudio property.
import { defineConfig } from "cypress";
export default defineConfig({
e2e: {
experimentalStudio: true // add this option!
},
});
For this project, we need to ensure that TypeScript is configured properly for Cypress when it runs, as it conflicts with the one in our root folder.
We will extend the original typescript configuration and override some properties.
Create a new tsconfig.json file inside the' cypress' folder.
{
"extends": "../tsconfig.json",
"include": [
"../node_modules/cypress",
"**/*.cy.ts"
],
"exclude": [],
"compilerOptions": {
"noEmit": false,
"sourceMap": false,
"target": "es5",
"lib": ["es5", "dom"],
"types": ["cypress"]
}
}
You can find more information on setting up TypeScript with Cypress in their documentation
Creating tests
Now that our setup is complete let's write our first test. We will create a folder called e2e and a new test file.
mkdir cypress/e2e
touch cypress/e2e/home.cy.ts
Open the new file and create an outline of your tests. Don't add anything to them. I initialized my file with a few tests.
describe("Home Page", () => {
it("there's a button with a counter", () => {
});
it("when clicking on the counter button, the count increases", ()=> {
});
it("when reloading the page, the count is reset to 0", () => {
});
})
There is an option to create spec files from the interface, but it will contain some initial content that you most likely remove. There’s third option to scaffold multiple specs files, these can serve as a learning resource for writing tests as it contains many different scenarios tested.
Make sure your app is running and, in another terminal, start cypress.
npm run cypress open
Select E2E testing and Chrome. You should now see a list with all your test files.
Click on home.cy.ts. Your tests will run and pass because we have not made any assertions.
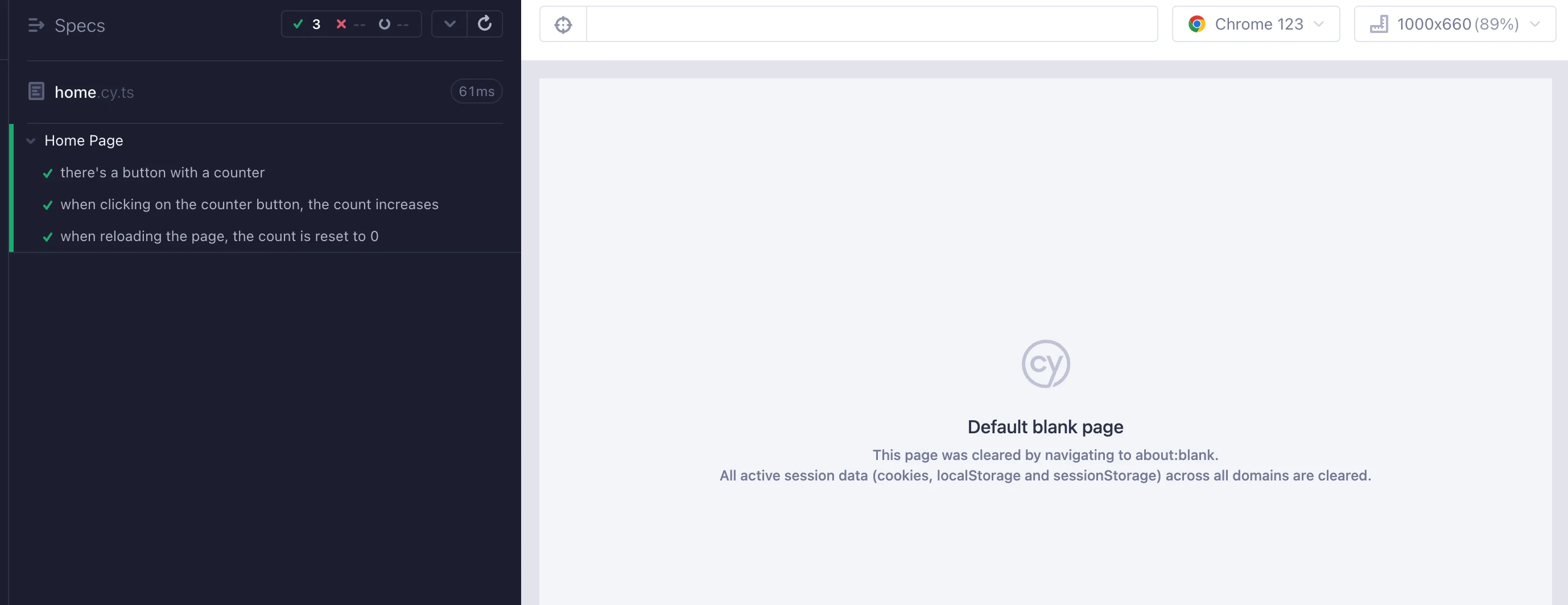
This looks the same as if we haven't enabled Studio, but there's a new detail added when you hover on any of the tests: a magic wand that you can click to start recording events and adding assertions directly in the UI.
Let's start with our first tests and check what assertions we can make. The first step is to navigate to a page. This interaction will be recorded and added to the test. To make assertions, right-click on an element and select the ones you want to add.

After we complete our test, let's review our generated code. Go to the test file and see the changes made to it. It should look something like this.
it("there's a button with a counter", () => {
/* ==== Generated with Cypress Studio ==== */
cy.visit('localhost:5173/');
cy.get('button').should('be.visible');
cy.get('button').should('be.enabled');
cy.get('button').should('have.text', 'count is 0');
/* ==== End Cypress Studio ==== */
});
Cypress Studio will attempt to pick the best selector for the element. In this case, it was able to choose button because it is unique to the page. If there were more buttons, the selector would've been different.
You can interact with elements as if you were using the page regularly. Note that Studio supports a limited set of commands: check, click, select, type, and uncheck.
Let's record our second test and verify that the button will increase its count when clicked.
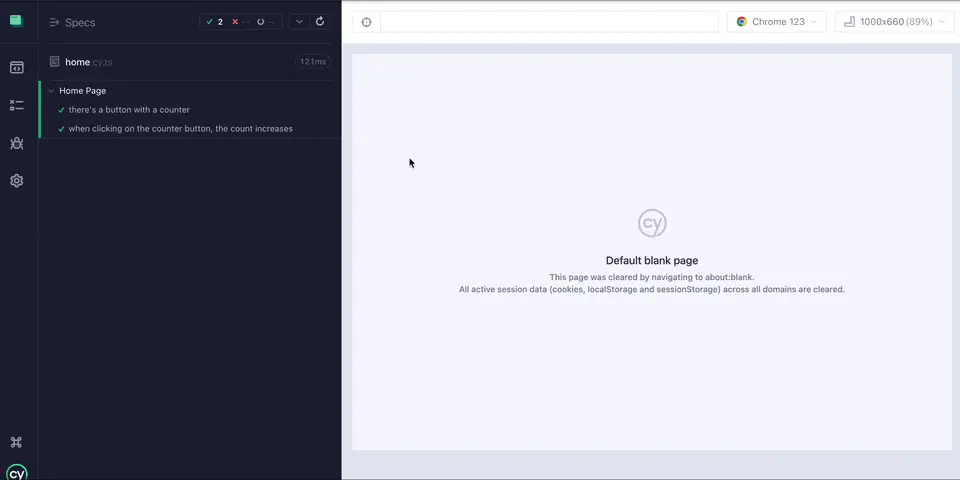
That was quick. Let's review our generated test.
it("when clicking on the counter button, the count increases", ()=> {
/* ==== Generated with Cypress Studio ==== */
cy.visit('localhost:5173/');
cy.get('button').should('have.text', 'count is 0');
cy.get('button').click();
cy.get('button').should('have.text', 'count is 1');
cy.get('button').click();
cy.get('button').should('have.text', 'count is 2');
cy.get('button').click();
cy.get('button').should('have.text', 'count is 3');
/* ==== End Cypress Studio ==== */
});
So far, our tests have been very accurate and didn't need any modifications. However, take Studio as a helper to write tests visually and their selector as suggestions. Let's take the bottom link with the text "SvelteKit" as an example.

It will generate the assertion:
cy.get(':nth-child(4) > .s-XsEmFtvddWTw').should('have.text', 'SvelteKit');
This selector is accurate, but modifying the elements' structure or order would break the tests.
We don’t want tests to break for reasons that do not affect our users. A change in order does not have the same impact for the user as changing the text of a button or changing the url of a link. These selectors should be as specific as possible, but rely as less as possible on implementation details. Selecting images by its alt attribute it’s a way to find a specific element and at the same time ensure that element is accessible. (Accessibility has a direct impact on users)
As a counterpart, when clicking any of the logos above, we will get very interesting selectors (and assertions).
cy.get('[href="https://vitejs.dev"] > .logo').should('have.attr', 'alt', 'Vite Logo');
cy.get('[href="https://svelte.dev"] > .logo').should('have.attr', 'alt', 'Svelte Logo');
With these assertions, we check that our images have an alt attribute set and are tied to a specified link.
Conclusion
As with any other automated tool, check the output and solve any issues that you may find. Results depend on the structure of the page and Cypress Studio's ability to choose an adequate selector. Overall, this tool can still help you write complex tests with plenty of interactions, and you can later modify any selectors. Besides the selector, I found it helpful in writing the assertions. If you’re new to Cypress or e2e testing, it can be of great help to go from an idea to a working test. Reviewing these tests can be a great way to learn how these tests are built.




