Bazel is a fast, scalable, incremental, and universal (for any languages/frameworks) build tool, and is especially useful for big mono repo projects.
I would like to write a series of blogs to introduce the concept of how to build a typescript project with Bazel.
- Chapter 1: Bazel Introduction
- Chapter 2: Bazel file structure and Bazel Query
- Chapter 3: Build/Develop/Test a typescript project
In chapter 1, I would like introduce basic Bazel concepts, and define some of the benefits we can expect from using Bazel.
- What is Bazel?
- Bazel: Correctness
- Bazel: Fast
- Bazel: Universal
- Bazel: Industrial grade
What is Bazel?
As you may know, we already have a lot of build tools. They include:
- CI tools: Jenkins/CircleCI
- Compile tools: tsc/sass
- Bundle tools: webpack/rollup
- Coordinate tools: make/grunt/gulp
So what is Bazel? Does it simply replace Jenkins or Webpack?
@AlexEagle helped us answer this question at ngconf 2019, but here is a great picture that will explain a little as well.

So Bazel is a build tool, used to coordinate other tools (compile/bundle tools), and will use all the existing tools (such as tsc/webpack/rollup) to do the underlying work.
Another graph, also from @AlexEagle, will show this relationship more clearly.

Ok, so Bazel is at the same position as Gulp, why not continue to use Gulp?
To answer this question, let's think about what the goal of the build tool is.
- Essential:
- Correct - don't need to worry about environmental pollution.
- Fast
- Incremental
- Parallelism
- Predictable - Same input will guarantee the same output.
- Reusable - Build logic can be easily composed and reused.
- Nice to have:
- Universal - support multiple languages and frameworks.
Correctness
This is the most important requirement. We all want our build systems to be stable, and we don't want them to generate unexpected results. Therefore, we want every build to be executed in an isolated environment. Otherwise, we will run into problems if, for example, we forget to delete some temp files, forget to reset environment variables, or if the build only works under certain conditions.
-
Sandboxing: Bazel supports sandboxing to isolate the environment. When we do a Bazel build, it will create an isolated working folder, and Bazel will run the build process under this folder. This is what we would call "sandboxing". Bazel will then restrict the access to the files outside of this folder. Also, Bazel makes sure that elements of the build tool, such as the compiler, only know their own input files, so the output will only depend on input.

-
The rule can only access an input file. Unlike a Gulp task, a Bazel rule can only access the files declared as input (we will talk about the target/rule in detail later).

Here is an example of a Gulp task:
gulp.task('compile', ['depTask'], () => {
// do compile
gulp.src(["a.ts"])
.pipe(tsc(...));
});
So inside of a Gulp task, there is just a normal function. There is no concept of Input, and dependencies only tells gulp to run tasks in a specified order, so the task can access any files, and use any environmental variables with no restrictions. Gulp will have no idea which files are used in this task, so if some logic depends on the unintended file access/environment reference, it is impossible for Gulp to guarantee that the task will always generate the same results.
Let's see a Bazel target.
ts_library(
name = "compile",
srcs = ["a.ts"],
)
We will talk about the Bazel target/rule in more detail in the next chapter. Here, we will declare a Bazel target with a ts_library rule. Unlike with a Gulp task, here we have a strict input which is srcs = ["a.ts"], so when Bazel decides to execute this target, the typescript compiler can only access the file a.ts inside of the sandbox, and nowhere else. Therefore, there is no way that the Bazel target will produce wrong results because of the unpredictable environment or input.
Fast
Bazel is incremental because Bazel is declarative and predictable.
Bazel is Declarative
Let's use Gulp to compile those two files, in order to demonstrate that Gulp is imperative and Bazel is declarative. Let's see an example with Gulp.
// gulpfile.js
gulp.task('compile', () => {
gulp.src(['user.ts', 'print.ts'])
.pipe(tsc(...))
.pipe(gulp.desc('./out'));
});
gulp.task('test', ['compile'], () => {
// run test depends on compile task
});
When we run gulp test for the first time, both the compile, and the test tasks will be executed. And then, even if we don't change any files, those two tasks will still be executed if we run gulp test again. Gulp is imperative, so we just have to tell it to do those two commands, and Gulp will do what we asked. Specifically, it checks the dependency, and guarantees the execution order. That's all.
Let's see how Bazel works. Here, we have two typescript files: user.ts, and print.ts. print.ts uses user.ts.
// user.ts
export class User {
constructor(public name: string) {}
toString() {
return `user: ${this.name}`;
}
}
// print.ts
import {User} from './user';
function printUser(user: User) {
console.log(`the user is ${user.name}`);
}
printUser(new User('testUser'));
To demonstrate that Bazel is declarative, let's use two Bazel build targets.
# src/BUILD.bazel
ts_library(
name = "user",
srcs = ["user.ts"],
)
ts_library(
name = "print",
srcs = ["print.ts"],
deps = [":user"]
)
So we declare two Bazel targets, user, and print. The print target depends on the user target. All those targets are using the ts_library rule. It contains the metadata to tell Bazel how to compile the typescript files. And again, all this information is just a definition. It's not about commands, so when you use Bazel to build those targets, it is up to Bazel to decide whether to execute those rules or not.
Let's see the result first.
When we run bazel build //src:print, both the user and print targets will be compiled, which makes sense. When we run bazel build //src:print again, you will find Bazel will not run any targets because nothing changed, and Bazel knows it. As a result, Bazel decides not to run any targets.
Let's change something in user.ts, and see what happens.
// updated user.ts
export class User {
constructor(public name: string) {}
toString() {
return `updated toString of user: ${this.name}`;
}
}
After we run bazel build //src:print again, we may expect that both user and print will be compiled once more because user.ts has been changed, and print.ts references user.ts, and the print target depends on the user target. But the result is that only the user target has been compiled, and the print target has not. Why?
This is because changes in user.ts don't impact print.ts, and Bazel understands this.
Let's check out the following graph, which describes the input/output of the target.

So for user target, the input is user.ts, and we have two outputs. One is user.js, and the other is user.d.ts. The latter of the two is the typescript declaration file. So let's see the relationship between the user, and print target.

Here, we can see that the print target depends on the user target, and that it uses one of the user target's outputs, user.d.ts, as it's own input. So, because we only updated toString of user.ts, and the user.d.ts was not changed at all, Bazel analyses the dependency graph. As a result, it knows that only user target needs to be built. Further, it also knows that the print target doesn't need to be built because the inputs of the print target, which are user.d.ts and print.ts, have not changed. Because of this, Bazel decides not to build print target.
It is very important to remember that Bazel is declarative and not imperative.
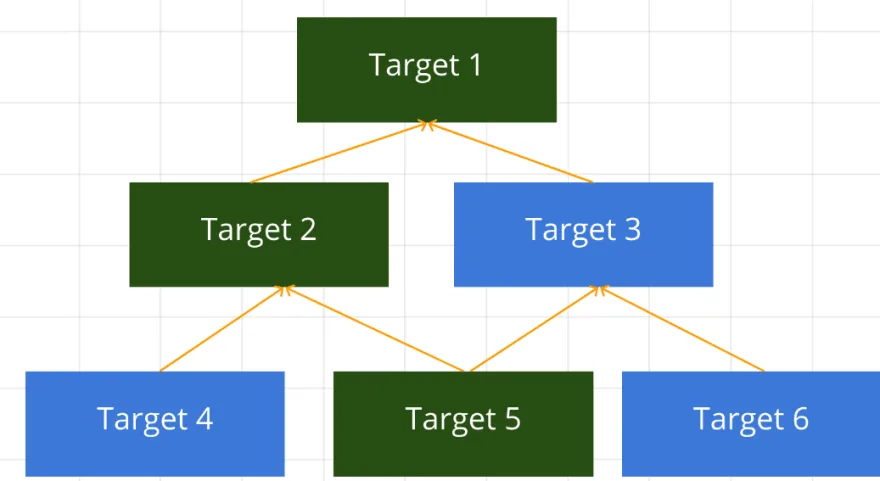
Bazel analyses the input/output of all build targets to determine which targets need to be executed.
(We can generate the dependency graph with bazel query, and we will talk about it in the next chapter.)
So Bazel can do incremental builds based on the analysis of the dependency graph, and only build the really impacted targets.
Bazel is Predictable (Bazel's Rules are Pure Functions)
Also, all Bazel rules are pure functions, so the same input will always result in the same output, hence Bazel is predictable. We can use the input as a key to cache the result of each target, and save the cache locally or remotely.
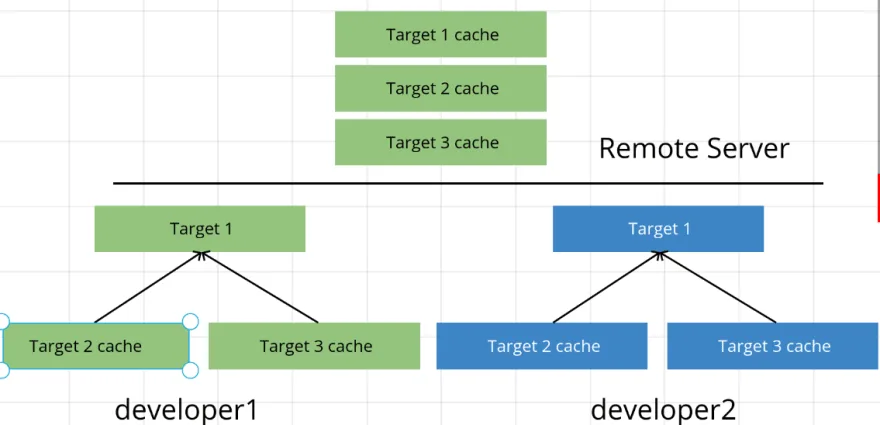
For example, developer 1 builds some targets, and pushes the result to remote cache. The other developer can then directly use this cache without building those targets in their own environment.
So these amazing features make Bazel super fast.
Universal
Bazel is a coordinate tool. It doesn't rely on any specified languages/frameworks, and it can build within almost all languages/frameworks from server to client, and from desktop to mobile.
It is difficult and costly to employ a specialist team to handle builds with several build tools/frameworks when working on a full-stack project. In one of my previous projects, we used Maven to build a Java backend, used Webpack to build its frontend, and used XCode and Gradle to build iOS and Android clients. Consequently, we needed a special build team consisting of people that knew all of those build tools, which makes it very difficult to do an incremental build, cache the results, or share the build script with other projects.
Bazel is also a perfect tool for mono repo, and full-stack projects that include multiple languages/frameworks.
Industrial Grade
Bazel is not an experimental project. It is used in almost all projects inside Google. When I started contributing to Angular, I did not use Bazel. Because of this, the time that Angular CI was taking was about 1 hour. Once Bazel was introduced to Angular CI, the time reduced to about 15 minutes, and the build process became much more stable, and less flaky than before, even with double the amount of test cases. It is amazing! I believe that Bazel will be the "must have" tool for many big projects.
I really like Bazel, and in the next blog post, I would like to introduce Bazel's file structure with bazel query.
Thanks for reading, and any feedback is appreciated.



