The <canvas> element and the Canvas API let us draw graphics via JavaScript. However, its Imperative API can be converted into a Declarative one using Svelte.
The technique to achieve this will require you to use what is sometimes called Renderless Components.
Renderless Components
In Svelte, all the sections of a .svelte file are optional, including the template.
This allows us to create a component that will not be rendered, but can contain some logic in the <script> section.
Let's create a new project. I'll be using Vite and Svelte for this tutorial.
npm init vite
✔ Project name: canvas-svelte
✔ Select a framework: › svelte
✔ Select a variant: › svelte-ts
cd canvas-svelte
npm i
Now that our project is ready, let's create a new component.
<!-- src/lib/Renderless.svelte -->
<script>
console.log("No template");
</script>
We will be printing a message to the console when the component is initialized.
Let's see how it works by making some changes to the entry point of our application.
// src/main.ts
// import App from './App.svelte'
import Renderless from './lib/Renderless.svelte'
const app = new Renderless({
target: document.getElementById('app')
})
export default app
If we start our server and open the developer tools in our browser, we will see the message printed.
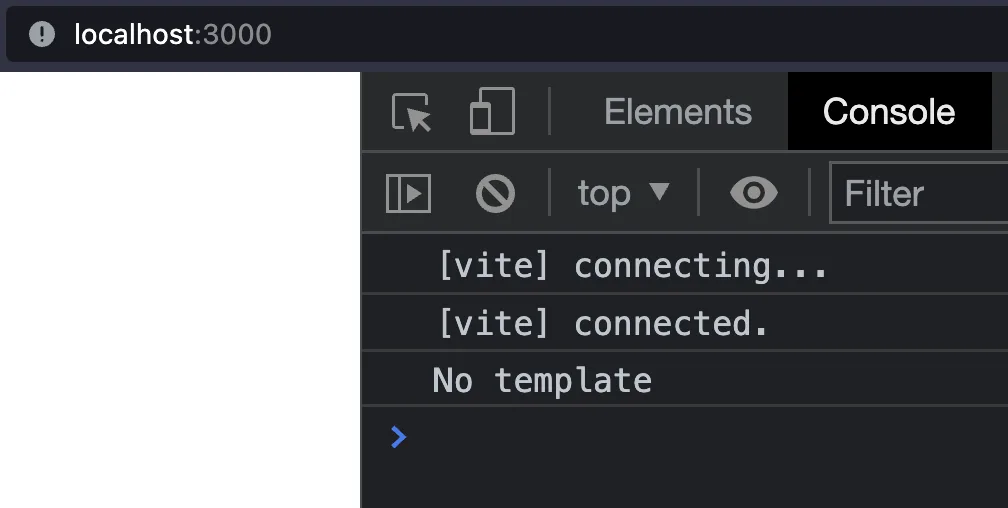
It's working.
Note that this component, even if it doesn't have a template, still behaves as a regular component instance, and you will still have access to the component Lifecycle methods.
Let's test it.
<!-- src/lib/Renderless.svelte -->
<script>
import { onMount } from "svelte";
console.log("No template");
onMount(() => {
console.log("Component mounted");
});
</script>
We added a second message to be shown after the component is mounted.
Both messages are now printed in the expected order.
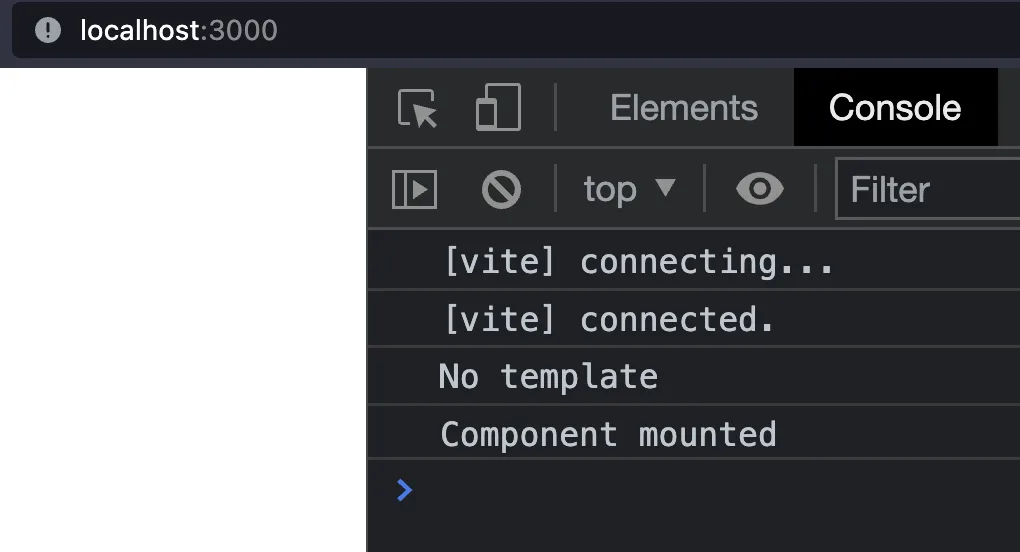
This means that we can use our Renderless Component just as any other Svelte Component.
Let's revert the changes to the main.ts file, and "render" the component inside the App component.
// src/main.ts
import App from './App.svelte'
const app = new App({
target: document.getElementById('app')
})
export default app
<!-- src/App.svelte -->
<script lang="ts">
import { onMount } from "svelte";
import Renderless from "./lib/Renderless.svelte";
console.log("App: initialized");
onMount(() => {
console.log("App: mounted");
});
</script>
<main>
<Renderless />
</main>
Finally, let's also modify our Renderless component to log more meaningful messages.
<!-- src/lib/Renderless.svelte -->
<script>
import { onMount } from "svelte";
console.log("Renderless: initialized");
onMount(() => {
console.log("Renderless: mounted");
});
</script>
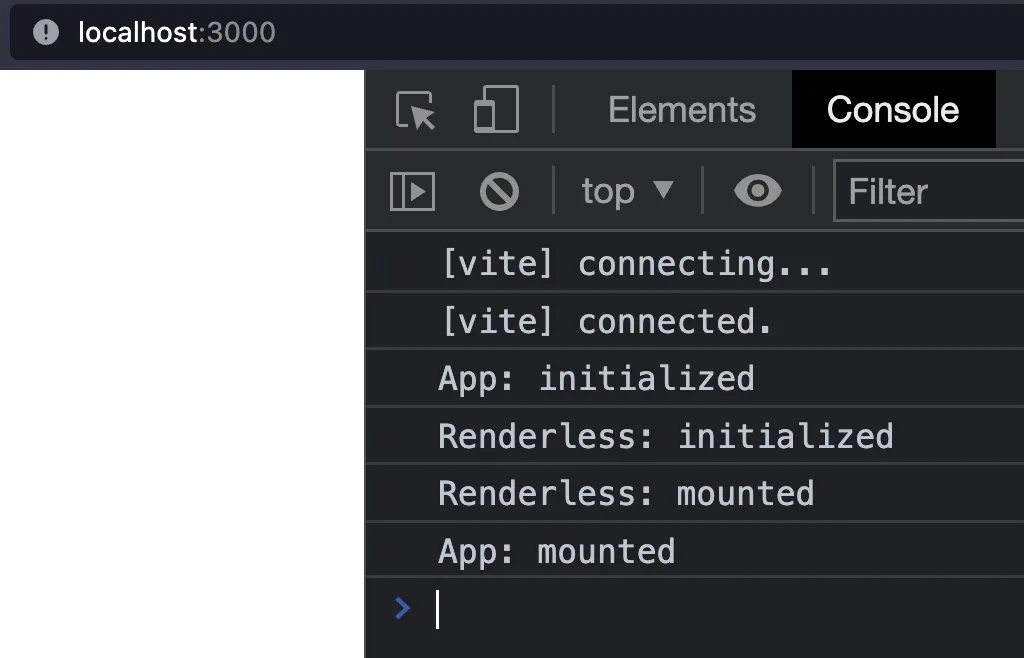
It's important to note the order of initialization and mounting of the components. This will be important when we create our Canvas and renderless Components.
There's a third way to mount our component and that's passing it as a child of another component. This is also called content projection. And the way that we do this is by using slots.
Let's create a container component that will render elements in a slot. I will also add more elements that will live along with the
<!-- src/lib/Container.svelte -->
<script>
import { onMount } from "svelte";
console.log("Container: initialized");
onMount(() => {
console.log("Container: mounted");
});
</script>
<h1>The container of things</h1>
<slot />
<p>invisible things</p>
Let's also add a prop to the Renderless component to add some kind of identifier to it.
<!-- src/lib/Renderless.svelte -->
<script lang="ts">
import { onMount } from "svelte";
export let id:string = "NoId"
console.log(`Renderless ${id}: initialized`);
onMount(() => {
console.log(`Renderless ${id}: mounted`);
});
</script>
Finally, in our App, we update the template to use the container, and pass multiple instances of Renderless to it.
<!-- src/App.svelte -->
<script lang="ts">
import { onMount } from "svelte";
import Container from "./lib/Container.svelte";
import Renderless from "./lib/Renderless.svelte";
console.log("App: initialized");
onMount(() => {
console.log("App: mounted");
});
</script>
<main>
<Container>
<Renderless id="Foo"/>
<Renderless id="Bar"/>
<Renderless id="Baz"/>
</Container>
</main>
Now, we can see the rendered Container and the renderless components logging when they are initialized and mounted.
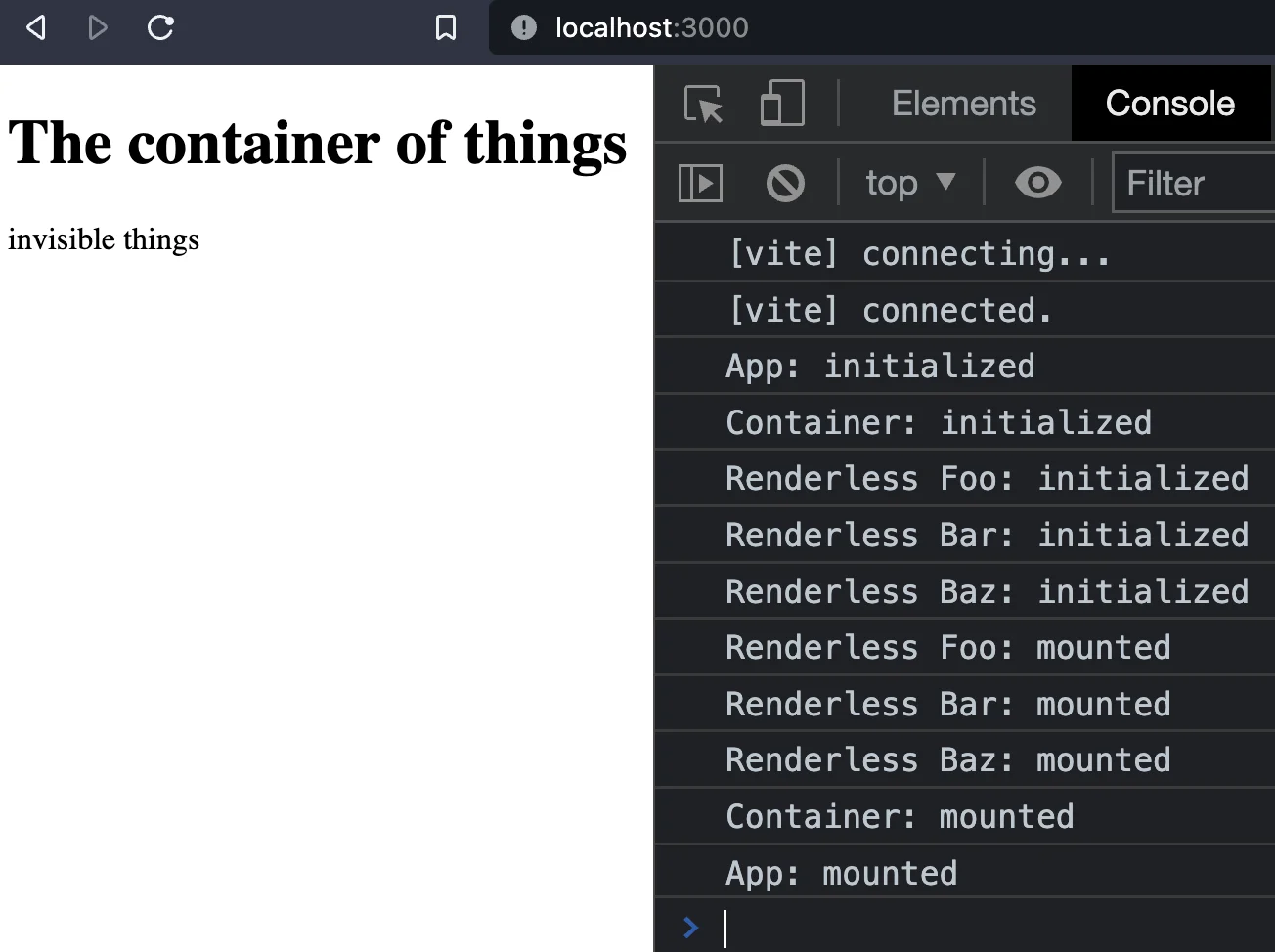
Now that we've learned about renderless components, let's use them with the <canvas> element.
<canvas> and the Canvas API
The canvas element cannot contain any children, except for a fallback element to render. Anything that you may want to render inside the canvas must be done using its imperative API.
Let's create a new Canvas component and render an empty canvas.
<!-- src/lib/Canvas.svelte -->
<script>
import { onMount } from "svelte";
console.log("Canvas: initialized");
onMount(() => {
console.log("Canvas: mounted");
});
</script>
<canvas />
Update the App component to import and use Canvas.
<!-- src/App.svelte -->
<script lang="ts">
import { onMount } from "svelte";
import Canvas from "./lib/Canvas.svelte";
console.log("App: initialized");
onMount(() => {
console.log("App: mounted");
});
</script>
<main>
<Canvas />
</main>
If we open the browser dev tools, we should see a canvas element rendered now.
Rendering elements inside canvas
As mentioned previously, we cannot add elements to draw inside our canvas. We have to use the API to do it.
To get a reference to the element, we will use the bind:this directive.
It's important to understand that, to use the API, we need the element to be available. This means that we will have to draw after the component is mounted.
<script lang="ts">
import { onMount } from "svelte";
let canvasElement: HTMLCanvasElement
console.log("1", canvasElement) // undefined!!!
console.log("Canvas: initialized");
onMount(() => {
console.log("2", canvasElement) // OK!!!
console.log("Canvas: mounted");
});
</script>
<canvas bind:this={canvasElement}/>
Now let's draw a line (I'm removing all the logging from the component for clarity).
<script lang="ts">
import { onMount } from "svelte";
let canvasElement: HTMLCanvasElement
onMount(() => {
// get canvas context
let ctx = canvasElement.getContext("2d")
// draw line
ctx.beginPath();
ctx.moveTo(10, 20); // line will start here
ctx.lineTo(150, 100); // line ends here
ctx.stroke(); // draw it
});
</script>
<canvas bind:this={canvasElement}/>
To draw, we need the canvas context. So we must do it after mounting the component. Then, we can start drawing using the canvas API.
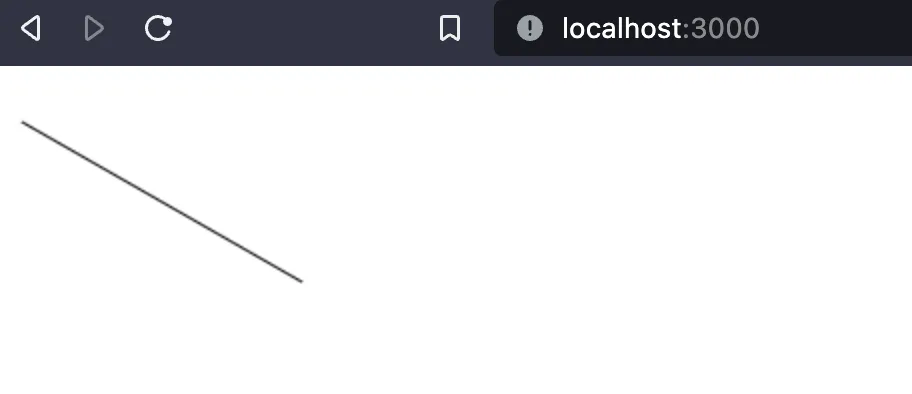
If we want to add a second line, we would have to add a new block of code.
<script lang="ts">
import { onMount } from "svelte";
let canvasElement: HTMLCanvasElement
onMount(() => {
// get canvas context
let ctx = canvasElement.getContext("2d")
// draw first line
ctx.beginPath();
ctx.moveTo(10, 20); // line will start here
ctx.lineTo(150, 100); // line ends here
ctx.stroke(); // draw it
// draw second line
ctx.beginPath();
ctx.moveTo(10, 40); // line will start here
ctx.lineTo(150, 120); // line ends here
ctx.stroke(); // draw it
});
</script>
We can see that we are starting to add more and more code to our component just by drawing simple shapes. This can get out of hand quickly. We can create helper functions to draw the lines.
<script lang="ts">
import { onMount } from "svelte";
let canvasElement: HTMLCanvasElement;
onMount(() => {
// get canvas context
let ctx = canvasElement.getContext("2d");
// draw first line
drawLine(ctx, [10, 20], [150, 100]);
// draw second line
drawLine(ctx, [10, 40], [150, 120]);
});
type Point = [number, number];
function drawLine(ctx: CanvasRenderingContext2D, start: Point, end: Point) {
ctx.beginPath();
ctx.moveTo(...start); // line will start here
ctx.lineTo(...end); // line ends here
ctx.stroke(); // draw it
}
</script>
<canvas bind:this={canvasElement} />
The code becomes more readable, but we are still delegating all the responsibility to the Canvas component, which will translate into having a very complex component.
We can avoid this by using renderless components and the Context API.
We know a few things so far:
- We require the Canvas context to draw.
- We can get the context after the component is mounted.
- Child components are mounted before the parent component.
- Parent components are initialized before child components.
- We can use
to mount child components.
We want to split our component into multiple. For this example, we want the Line component to draw itself.
Canvas and Line are coupled. A Line component cannot be drawn without a Canvas, and it needs the canvas context. The problem is that the context is not available when we mount the Child component (Line is mounted before Canvas), so we need a different approach.
Instead of passing the context to draw itself, we will let the parent component know that a child component needs to be drawn.
We'll communicate the Canvas and Line components using Context.
Context is a way for two or more components to communicate. Context can only be set or retrieved during initialization, which is what we need in our case. Remember that Canvas is initialized before our Line component.
Let's start by moving the line rendering to its own component. I will also move some types to their own file to be shared across components.
// src/types.ts
export type Point = [number, number];
export type DrawFn = (ctx: CanvasRenderingContext2D) => void;
export type CanvasContext = {
addDrawFn: (fn: DrawFn) => void;
removeDrawFn: (fn: DrawFn) => void;
};
<!-- src/lib/Line.svelte -->
<script lang="ts">
import type { Point } from "./types";
export let start: Point;
export let end: Point;
function draw(ctx: CanvasRenderingContext2D) {
ctx.beginPath();
ctx.moveTo(...start);
ctx.lineTo(...end);
ctx.stroke();
}
</script>
This is very similar to what we had in our Canvas component, but abstracted to a reusable component. Now we need a Communicate Canvas and Line components.
Our Canvas will work as the orchestrator of all the rendering.
It will initialize all the Child components, gather the rendering functions, and draw them when required.
<script lang="ts">
import { onMount, setContext } from "svelte";
import type { DrawFn } from "./types";
let canvasElement: HTMLCanvasElement;
let fnsToDraw = [] as DrawFn[];
setContext("canvas", {
addDrawFn: (fn: DrawFn) => {
fnsToDraw.push(fn);
},
removeDrawFn: (fn: DrawFn) => {
let index = fnsToDraw.indexOf(fn);
if (index > -1){
fnsToDraw.splice(index, 1);
}
},
});
onMount(() => {
// get canvas context
let ctx = canvasElement.getContext("2d");
draw(ctx);
});
function draw(ctx){
fnsToDraw.forEach(draw => draw(ctx));
}
</script>
<canvas bind:this={canvasElement} />
<slot />
The first thing to note is that our template has changed and now we have a <slot> element beside our canvas. It will be used to mount any children that we pass into our canvas-- in our case, the Line components. These will not add any HTML element.
In the script section, we added an array to hold all the render functions to draw.
We also set a new context. This has to be done during initialization. Our Canvas is initialized before Line, so we set two methods here. These are methods to add and remove a function from our array that holds them. Then any Child component can have access to this context, and call its methods.
That's exactly what we'll do next in the Line component.
<script lang="ts">
import { getContext, onDestroy, onMount } from "svelte";
import type { Point, CanvasContext } from "./types";
export let start: Point;
export let end: Point;
let canvasContext = getContext("canvas") as CanvasContext;
onMount(() => {
canvasContext.addDrawFn(draw);
});
onDestroy(() => {
canvasContext.removeDrawFn(draw);
});
function draw(ctx: CanvasRenderingContext2D) {
ctx.beginPath();
ctx.moveTo(...start);
ctx.lineTo(...end);
ctx.stroke();
}
</script>
We register the function using the context previously set by Canvas when we mount this component. We could do it on initialization too because we know that context will be available anyway. But I prefer doing it after the component is mounted. And when the element is destroyed, it removes itself from the list of rendering functions.
Finally, let's update our App to use the new Canvas and Line components.
<script lang="ts">
import Canvas from "./lib/Canvas.svelte";
import Line from "./lib/Line.svelte";
</script>
<main>
<Canvas>
<Line start={[10, 20]} end={[150, 100]} />
<Line start={[10, 40]} end={[150, 120]} />
</Canvas>
</main>
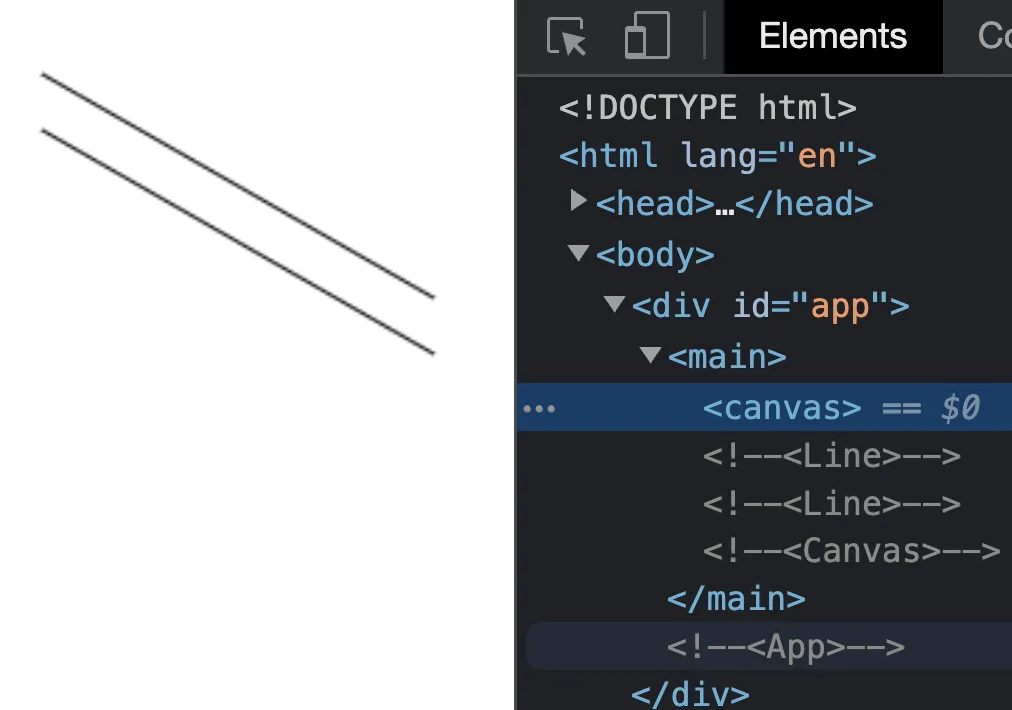
We've successfully updated our Canvas component to use a declarative approach. A few things are missing though. We are only drawing once when the Canvas component is mounted.
We need to make the canvas render frequently to update itself when changes happen (unless you only want to render once). Note that we would have to do it with or without the approach we've taken. And it's a common way of updating the canvas contents.
<script lang="ts">
// NOTE: some code removed for readability
// ...
let frameId: number
// ...
onMount(() => {
// get canvas context
let ctx = canvasElement.getContext("2d");
frameId = requestAnimationFrame(() => draw(ctx));
});
onDestroy(() => {
if (frameId){
cancelAnimationFrame(frameId)
}
})
function draw(ctx: CanvasRenderingContext2D) {
if (clearFrames) {
ctx.clearRect(0,0,canvasElement.width, canvasElement.width)
}
fnsToDraw.forEach((fn) => fn(ctx));
frameId = requestAnimationFrame(() => draw(ctx))
}
</script>
We achieve this rerendering of the canvas using the requestAnimationFrame method. The callback passed in will be run before the browsers' repaint.
First, we create a new variable to assign the current frameId (required for canceling the animation). Then, when we mount the component, we invoke requestAnimationFrame and assign the returned id to our variable. So far, the end result is as before. The difference is now in our draw function that will request a new animation frame each time after being drawn. We will also clear our canvas by default. Otherwise, when we are animating, each frame would be drawn on top of each other (This might be the desired effect. In that case the clearFrame prop can be set to false). Our canvas will update each frame until we destroy our component and cancel any current animation using the id previously stored.
Adding more features
The basic functionality for the components is working, but we may want to add more features.
For this example, we will be exposing two events: onmousemove and onmouseleave.
To do this, we need to add a few things two our Canvas component.
In the template, change the canvas element to this:
<canvas on:mousemove on:mouseleave bind:this={canvasElement} />
Now, the events can be handled in our App:
<script lang="ts">
import Canvas from "./lib/Canvas.svelte";
import Line from "./lib/Line.svelte";
import type { Point } from "./lib/types";
function followMouse(e) {
let rect = e.target.getBoundingClientRect();
end = [e.clientX - rect.left, e.clientY - rect.top];
}
let start = [0, 0] as Point;
let end = [0, 0] as Point;
</script>
<main>
<Canvas
on:mousemove={(e) => followMouse(e)}
on:mouseleave={() => {
end = [0, 0];
}}
>
<Line {start} {end} />
</Canvas>
</main>
Svelte is responsible for updating the end position of the line. But our Canvas component is the one used to update the canvas content (using requestAnimationFrame).
Wrapping up
I hope this tutorial helps you as an introduction to use canvas in Svelte, but also to understand how we can turn a library with an Imperative API into a more declarative one.
There are a few examples of these ideas with more complex examples using a similar approach, like svelte-cubed or svelte-leaflet.
From the svelte-cubed docs:
This ...
import * as THREE from 'three';
function render(element) {
const scene = new THREE.Scene();
const camera = new THREE.PerspectiveCamera(
45,
element.clientWidth / element.clientHeight,
0.1,
2000
);
const renderer = new THREE.WebGLRenderer();
renderer.setSize(element.clientWidth / element.clientHeight);
element.appendChild(renderer.domElement);
const geometry = new THREE.BoxGeometry();
const material = new THREE.MeshNormalMaterial();
const box = new THREE.Mesh(geometry, material);
scene.add(box);
camera.position.x = 2;
camera.position.y = 2;
camera.position.z = 5;
camera.lookAt(new THREE.Vector3(0, 0, 0));
renderer.render(scene, camera);
}
becomes...
<script>
import * as THREE from 'three';
import * as SC from 'svelte-cubed';
</script>
<SC.Canvas>
<SC.Mesh geometry={new THREE.BoxGeometry()} />
<SC.PerspectiveCamera position={[1, 1, 3]} />
</SC.Canvas>
We just scratched the surface of the Canvas API, but you can extend it for your own needs, or even create a library for it!




