Recently, Perfbuddy has transitioned its backend stack to utilize Serverless when managing the AWS Amplify backend, in favor of using pure Amplify. I was brought on near the end of that process to lend a hand, after previously wrapping up migrating another project's backend over to the Serverless framework. Out of the tasks I helped with, one of the bigger challenges came from setting up custom domains for our API endpoints that the frontend would point to.
That is, instead of a difficult-to-keep-track-of URL generated by AWS, we can use a custom domain such as api.perfbuddy.com that points to an API Gateway domain where the API routes are set up. Much more developer friendly to remember, especially if you have multiple environments set up for various stages. Fortunately, Serverless has a plugin called Domain Manager that can handle all of that for us.
The potential problem? The site had already deployed in a production state inside of another AWS account, and its domain was registered to that account -- separately from where the Serverless backend was being set up. There is a process to migrate that, but having never done it before and the site needing to stay live, I decided to see if I could make it work as it was. Fortunately, I was able to.
Prerequisite
Before we take a deeper look, if you're following along looking to solve a similar problem and you haven't yet started your Serverless migration, we've discussed that process previously in detail, and you'll definitely want to have the basics already set up for your Serverless deployment instead of doing this all in one go.
If you're already deploying with Serverless, you probably also have an IAM role created and set up with the permissions you'll be needing. Just to be sure, you'll be needing these permissions:
acm:ListCertificates *
apigateway:GET /domainnames/*
apigateway:GET /domainnames/*/basepathmappings
apigateway:DELETE /domainnames/*
apigateway:POST /domainnames
apigateway:POST /domainnames/*/basepathmappings
apigateway:PATCH /domainnames/*/basepathmapping
cloudformation:GET *
cloudfront:UpdateDistribution *
route53:ListHostedZones *
route53:ChangeResourceRecordSets hostedzone/{HostedZoneId}
route53:GetHostedZone *
route53:ListResourceRecordSets *
iam:CreateServiceLinkedRole arn:aws:iam::${AWS::AccountId}: role/aws-service-role/ops.apigateway.amazonaws.com/AWSServiceRoleForAPIGateway
The Problem
As I stated previously, the Perfbuddy domain was registered in a separate AWS account than the one our new Serverless deployment was in under our organization account. Fortunately, I had access to both accounts so either a) I could make this work or b) I would have to migrate the domain over and be a nervous wreck the whole time that I'd break something.
My first step was just to naively follow the excellent Serverless Domain Manager plugin guide, which got me most of the way there. I added the plugin to the project:
npm install serverless-domain-manager --save-dev
Then, added the plugin to the the serverless.yml:
plugins:
- serverless-domain-manager
Note: You'll want to make sure you pay attention to the order of your plugins, since for some plugins, the order matters greatly. If you've been paying attention to the order of your plugins already, you probably know whether or not if it's safe to list it first, last, etc. For my purposes, I added it to the end of the list without issue.
Next, I needed to add the plugin configuration under the custom field:
custom:
customDomain:
domainName: api.perfbuddy.com
certificateName: '*.perfbuddy.com'
endpointType: 'regional'
apiType: http
The documentation specifies multiple ways to set up multiple domains in one configuration setup, but for my first attempt, I decided to try to get just one domain setup to see if it worked (more on setting up multiple domains later). I left out a few of the parameters that were listed in the guide, and only added a few that I knew I needed to specify. Most parameters have a default value if not specified, which you can find on the plugin's Github.
After running the create command:
serverless create_domain
I hit my first real snag: there was no hosted zone set up for the custom domain.
The Solution
At this step, I feared I would actually potentially have to migrate the domain over. However, when reading the migration documentation, I noticed a specific line in the second optional step that would clue me in on exactly what I needed to know. It reads as follows:
If you're using Route 53 as the DNS service for the domain, Route 53 doesn't transfer the hosted zone when you transfer a domain to a different AWS account. If domain registration is associated with one account and the corresponding hosted zone is associated with another account, neither domain registration nor DNS functionality is affected. The only effect is that you'll need to sign into the Route 53 console using one account to see the domain, and sign in using the other account to see the hosted zone.
So, since I had access to both accounts under the same organization, it read to me that AWS would handle the DNS automatically without transferring anything. A hosted zone can live on one account while the main domain registration lived on the other. Perfect.
Navigating to the Route 53 console where the Serverless backend was being deployed, I created a hosted zone under the exact domain name I wanted to deploy to (I also created hosted zones for the other specific domains I would need):
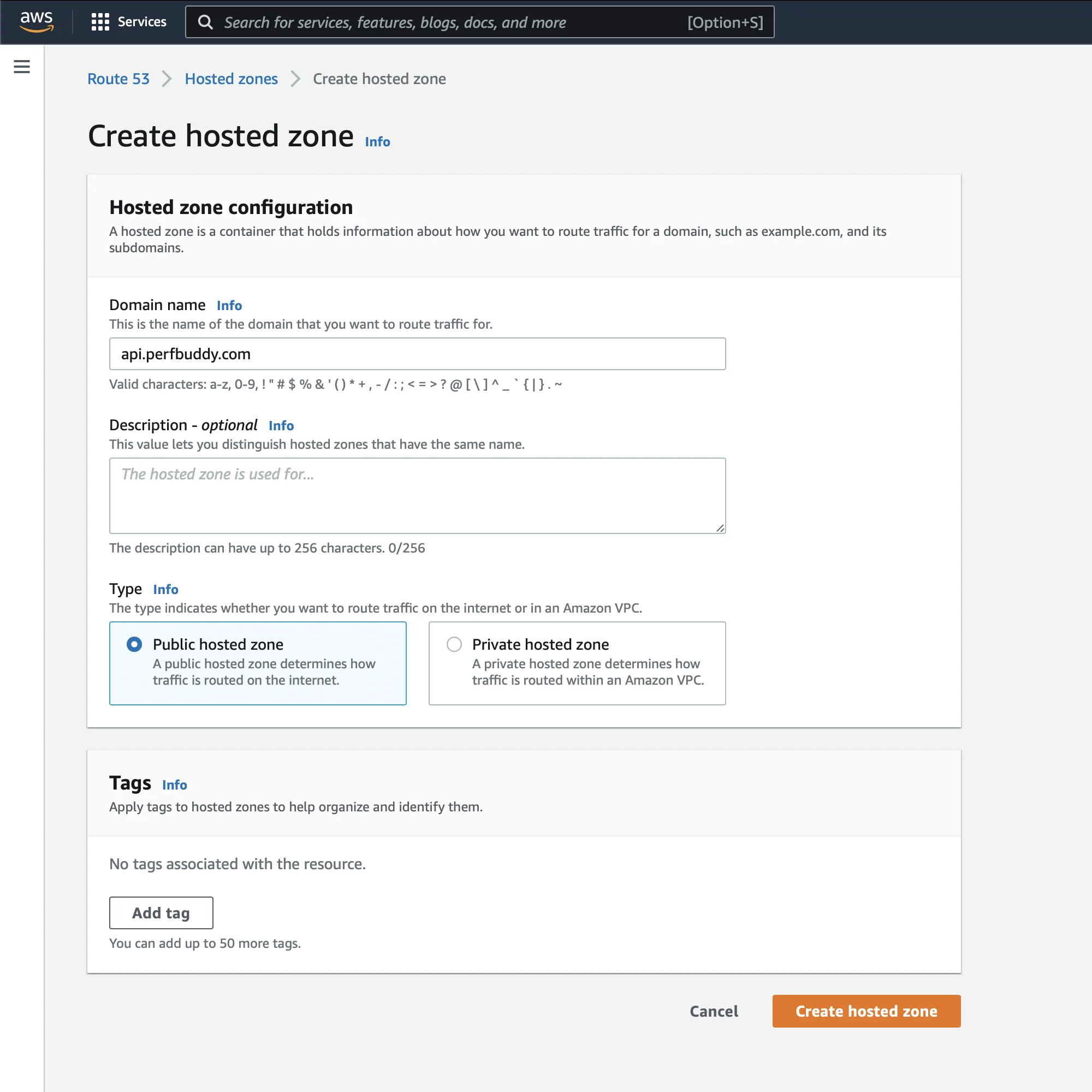
At this point, the Serverless CLI may have worked with the configuration we specified as is, but I decided to add an additional parameter using the hosted zone ID from the one I just created:
custom:
customDomain:
domainName: api.perfbuddy.com
certificateName: '*.perfbuddy.com'
endpointType: 'regional'
apiType: http
hostedZoneId: 'redacted-hosted-zone-id'
Now, running the create_domain worked and navigating to the API Gateway console showed the custom domain we just created:
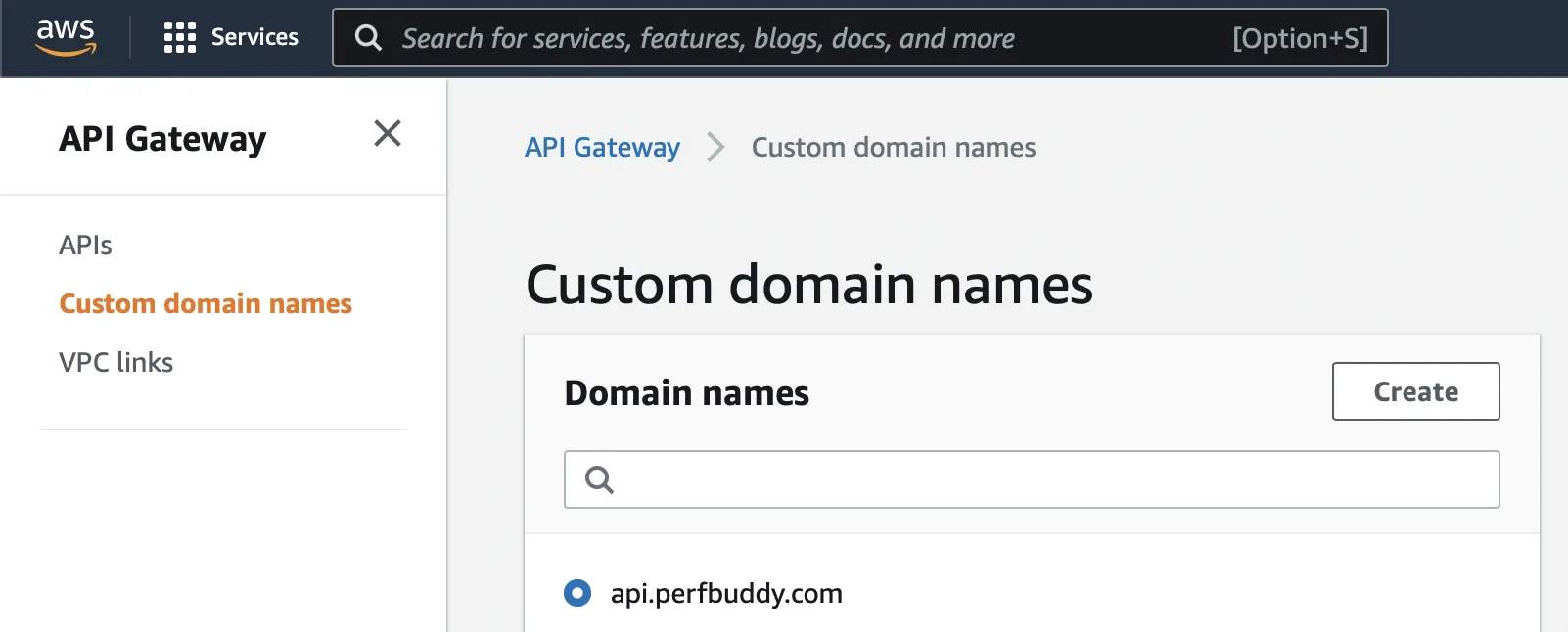
Additionally, navigating back to our hosted zone in the Route 53 console, we created shows two additional records the plugin created for us. Finally, running a deploy command:
serverless deploy
Successfully deployed the backend, now with the domain manager plugin info appearing in the output:
Serverless Domain Manager:
Domain Name: api.perfbuddy.com
Target Domain: [AWS target domain that matches with API Gateway custom domain target]
Hosted Zone Id: [Hosted zone ID that matches with API Gateway custom domain hosted zone ID]
Deploying Multiple Domains
Of course, it wasn't just a single API backend I needed to setup; I needed to setup multiple. The problem I saw with using the plugin's built-in capability for multiple domains was that it would try to deploy to all of them at the same time. We needed to deploy to different stages, at different points of development and release independently between them.
So, utilizing the Serverless stage parameters I was able to use the same single custom domain structure for the domain manager plugin configuration. You can even specify whole arrays as a parameter, so I did exactly that (with the other stages and parameters added as needed, of course):
params:
prod:
customDomain:
domainName: api.perfbuddy.com
stage: prod
endpointType: 'regional'
certificateName: '*.perfbuddy.com'
hostedZoneId: 'your-hosted-zone-id'
apiType: http
Note: Be sure to take note that you are using the correct YAML formatting and structure for you use case -- at one point, I was using the multiple domains YAML structure, but incorrectly so my deployments weren't actually going through as a result, I believe. I spent far more time resolving that specifically than I needed to.
Then, back under the actual plugin configuration, I changed it as follows:
custom:
customDomain: ${param:customDomain}
Now, running any of the commands:
serverless deploy --stage prod
serverless deploy --stage stage
serverless deploy --stage dev
Deployed to all needed environments separately, and pointing my locally running frontend to api.perfbuddy.com worked like a charm:
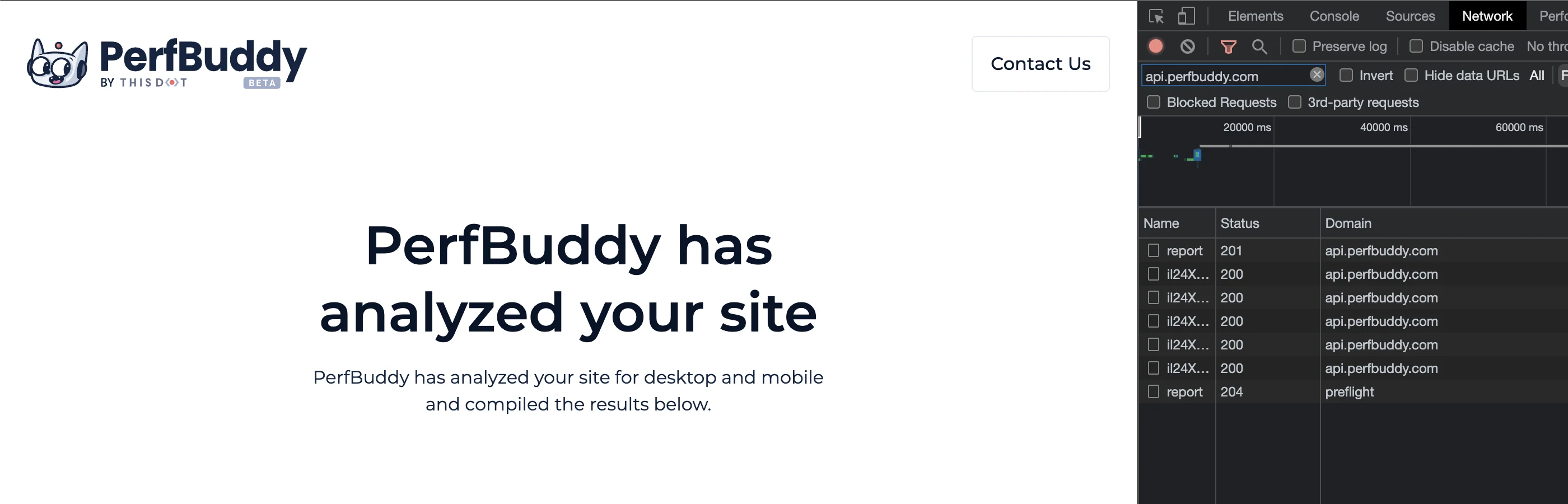
Conclusion
Working in Serverless truly has been a smooth process, and we're constantly blown away with its power that can only succinctly be described as magic. And, of course, if you haven't yet checked out Perfbuddy, be sure to do so! It's completely free and was made to help all developers and their teams improve their products.




