Intro to Svelte
Svelte is a JavaScript tool that may look similar to other frameworks, or have similar concepts, but it works differently, making it stand out from the rest. Svelte is reactive by nature, and instead of using a virtual dom, it will directly update the DOM in an efficient way.
It is possible to achieve this by delegating its work to a compile step, which will make the framework itself "disappear", and will ship some optimized vanilla JavaScript code.
Let's take a look at an example of a Svelte component.
<!-- App.svelte -->
<h1>This is Svelte</h1>
<p class="omg">It looks like regular html</p>
As you can see, at a first glance, it is no different than plain old HTML (for a non-dynamic component). You can keep using the class keyword.
Let's add some CSS to our component.
<!-- App.svelte -->
<h1>This is Svelte</h1>
<p class="omg">It looks like regular html</p>
<p class="styled">CSS rocks!</p>
<style>
h1 {
font-size: 30px;
}
.styled {
color: red;
}
</style>
Once again, this looks like regular CSS, and that's because it is regular CSS.
How about adding some JS to it?
<!-- App.svelte -->
<script>
function logSomething(something) {
console.log(something);
}
logSomething('it works');
</script>
<h1>This is Svelte</h1>
<p class="omg">It looks like regular html</p>
<p class="styled">CSS rocks!</p>
<style>
h1 {
font-size: 30px;
}
.styled {
color: red;
}
</style>
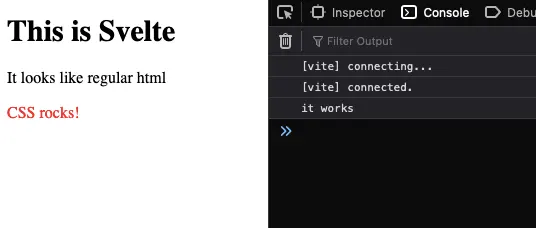
So, we have HTML that looks like HTML, CSS that looks like CSS, and JavaScript that looks like JavaScript, all packed in a single svelte file.
Of course, this is not everything Svelte has to offer.
How to start a new Svelte project
To start a svelte project, you can use the command npx degit [sveltejs/template](https://github.com/sveltejs/template) my-svelte-project as suggested on their website, but my preferred way of doing it these days is to use vite.
Both methods can be set up to use TypeScript.
Let's create a new project.
npm init @vitejs/app
✔ Project name: · my-svelte-project
✔ Select a framework: · svelte
✔ Select a variant: · TypeScript
cd my-svelte-project
pnpm install //use the package manager you prefer
pnpm run dev
Now that our project is created, it will have a folder structure that looks like this.
How do you do x in Svelte?
Let's create a new component to be able to test different features of Svelte. I will remove the default component created (Counter.svelte)
rm -rf src/lib/Counter.svelte // removes the component created by default
touch src/lib/Example.svelte // creates a new svelte component
We need to update App.svelte to import our new component and render it
<!-- App.svelte -->
<script>
import Example from './lib/Example.svelte';
</script>
<Example />
Using variables in the template
To use a variable in the template we need to:
Declare a variable in our <script>
Use the variable within brackets {} in the template
In our component:
<!-- src/lib/Example.svelte -->
<script lang="ts">
let greeting: string = 'Hi';
</script>
<p>{greeting}</p>
If you run the application with the command npm run dev, the project will start, and run by default on port 3000. Changes will be reflected in the browser.
props/inputs
To create an input we need to export a variable.
<!-- src/lib/Example.svelte -->
<script lang="ts">
export let name: string;
let greeting: string = 'Hi';
</script>
<span>{greeting}, {name}</span>
We will need to update our App to pass the value of name.
<!-- App.svelte -->
<script>
import Example from './lib/Example.svelte';
</script>
<Example name="John" />
Event
You can listen to events with the on directive.
Let's add an event to our span element in the Example component.
<script lang="ts">
export let name: string;
let greeting: string = 'Hi';
function toggleGreeting() {
if (greeting === 'Hi') {
greeting = 'Bye';
} else {
greeting = 'Hi';
}
}
</script>
<p>{greeting}, {name}</p>
<button on:click={toggleGreeting}>Toggle greeting</button>
You can now see the text changing when clicking on the button.
Sometimes you will need to pass a custom event from a child component to a parent component. To trigger a custom event we need to import and use the createEventDispatcher method.
<script lang="ts">
import { createEventDispatcher } from 'svelte';
const dispatch = createEventDispatcher();
export let name: string;
let greeting: string = 'Hi';
function toggleGreeting() {
if (greeting === 'Hi') {
greeting = 'Bye';
} else {
greeting = 'Hi';
}
}
function toggleName() {
dispatch('myCustomEvent');
}
</script>
<p>{greeting}, {name}</p>
<button on:click={toggleGreeting}>Toggle greeting</button>
<button on:click={toggleName}>Toggle Name</button>
We need to update our App component too, to do something with the event.
<script>
import Example from './lib/Example.svelte';
let name = 'John';
function onMyCustomEvent() {
if (name === 'John') {
name = 'Jane';
} else {
name = 'John';
}
}
</script>
<Example {name} on:myCustomEvent={onMyCustomEvent} />
This event can pass data using the second argument in the dispatch method.
<!-- src/lib/Example.svelte -->
<script lang="ts">
import { createEventDispatcher } from 'svelte';
const dispatch = createEventDispatcher();
export let name: string;
let greeting: string = 'Hi';
function toggleGreeting() {
if (greeting === 'Hi') {
greeting = 'Bye';
} else {
greeting = 'Hi';
}
let nextName;
if (name === 'John') {
nextName = 'Jane';
} else {
nextName = 'John';
}
}
function toggleName() {
let nextName;
if (name === 'John') {
nextName = 'Jane';
} else {
nextName = 'John';
}
dispatch('myCustomEvent', nextName);
}
</script>
<p>{greeting}, {name}</p>
<button on:click={toggleGreeting}>Toggle greeting</button>
<button on:click={toggleName}>Toggle Name</button>
<script>
import Example from './lib/Example.svelte';
let name = 'John';
function onMyCustomEvent(event) {
name = event.detail;
}
</script>
<Example {name} on:myCustomEvent={onMyCustomEvent} />
Now the Example component is emitting an event with the new name. And the App component is handling it.
Reactivity
One of the main features of svelte is that it makes reactivity so easy to reason about.
To include a reactive statement, you need to prepend it with $:.
The compiler will figure out when it should update the reactive values based on the variables that it depends on.
In our previous example:
<!-- src/lib/Example.svelte -->
<script lang="ts">
import { createEventDispatcher } from 'svelte';
const dispatch = createEventDispatcher();
export let name: string;
let greeting: string = 'Hi';
$: reactiveValue = `You're saying ${greeting} to ${name}`
function toggleGreeting() {
if (greeting === 'Hi') {
greeting = 'Bye';
} else {
greeting = 'Hi';
}
let nextName;
if (name === 'John') {
nextName = 'Jane';
} else {
nextName = 'John';
}
}
function toggleName() {
let nextName;
if (name === 'John') {
nextName = 'Jane';
} else {
nextName = 'John';
}
dispatch('myCustomEvent', nextName);
}
</script>
<p>{greeting}, {name}</p>
<p>{reactiveValue}</p>
<button on:click={toggleGreeting}>Toggle greeting</button>
<button on:click={toggleName}>Toggle Name</button>
In this example, reactiveVlaue is dependant on name and greeting. Whenever any of these values changes, reactiveValue will be updated.
Reactivity in Svelte will be triggered by assignments, which means that it's required to assign a value to make it work. Array.prototype.push is not an assignment, so it will not work.
Flow control
if/else You can change your template rendering based on some condition use if else. The syntax looks like this
{#if <condition>}
some code
{:else if}
more code
{:else}
more code
{/if}
The syntax is similar to other template modifiers. start with {# }, continue with {: } and end with {/ }.
each You can iterate over an array with an each block.
{#each anArray as item, i}
<span>{item.name}{/span}
{/each}
When iterating this way and modifying the array, items will be added or removed at the end of the block, and the values of the items will be updated accordingly.
If you need to keep track of each element, you can use a key. This is common for other frameworks too.
The syntax for this is:
{#each anArray as item (item.id)}
<span>{item.name}{/span}
{/each}
where the id is the unique key in this example.
Asynchronous rendering
Sometimes, you need to wait before rendering something (or not). We can make use of an async block in this case.
Similar to the other template modifiers, the syntax is like this.
{#await aPromise}
<p>Somthing to render while promise has not resolved
{:then value}
<p>If the promise is successful you can render the value: {value}</p>
{:catch error}
<p>There was an error: {error.message}</p>
{/await}
Stores
Another nice feature of svelte is stores, which provides a way of having global pieces of state in your application. They can be accessed anywhere in your application, and are reactive.
A readable store cannot be modified from the outside (like a component). A writable store can be accessed and updated from a component. The third kind of store is a derived store, which will depend on other stores, and update accordingly.
Let's share some state between components using a store:
// lib/stores.ts
import { writable } from 'svelte/store';
export const age = writable(32);
<!-- src/lib/Example.svelte -->
<script lang="ts">
import { createEventDispatcher } from 'svelte';```
import { age } from './stores.js';
const dispatch = createEventDispatcher();
export let name: string;
let greeting: string = 'Hi';
$: reactiveValue = `You're saying ${greeting} to ${name}`
function toggleGreeting() {
if (greeting === 'Hi') {
greeting = 'Bye';
} else {
greeting = 'Hi';
}
}
function toggleName() {
let nextName;
if (name === 'John') {
nextName = 'Jane';
} else {
nextName = 'John';
}
dispatch('myCustomEvent', nextName);
}
function toggleAge() {
age.update(value => value === 32 ? 35 : 32);
}
</script>
<p>{greeting}, {name}</p>
<p>{reactiveValue}</p>
<button on:click={toggleGreeting}>Toggle greeting</button>
<button on:click={toggleName}>Toggle Name</button>
<button on:click={toggleAge}>Toggle Age</button>
<!-- src/lib/Age.svelte -->
<script lang="ts">
import { age } from './stores';
</script>
<span>Your age is: {$age}</span>
<script>
import Example from './lib/Example.svelte';
import Age from './lib/Age.svelte';
let name = 'John';
function onMyCustomEvent(event) {
name = event.detail;
}
</script>
<Example {name} on:myCustomEvent={onMyCustomEvent} />
<Age />
Svelte is a fully-featured framework that shifts some of the load to the compiler process. There's more to it like animations and context. So make sure to keep an eye on it, and give it a try whenever you can.
Sapper
Sapper is a framework built on top of Svelte, which adds more to it like router navigations, SSG, and SSR. It never reached v1.0, but it led the way for the future of Svelte.
Svelte-Kit and the future
Announced last year, Svelte-Kit takes what's learned in Svelte and Sapper, and combines them into one single tool/framework, so you don't have to decide to either use Sapper or regular Svelte. It preserves the main features of Sapper, like file-based routing, SSR, and SSG. It's still in Beta, but you can try it today. (I already migrated a Sapper site). Svelte-Kit uses Vite by default.
If you want to give it a try, you can start a new project by running npm init svelte@next my-app.




