
Leveraging the power of GraphQL and NuxtJS
In this post, we will be exploring some of the ways GraphQL queries can be used with NuxtJS to build performant applications for different industries.
GraphQL and NuxtJS are probably the technologies with the most buzz in the tech world today.
GraphQL
When working with REST APIs, data is taken from specific endpoints. Each endpoint has a clearly defined structure of the information that it returns. This means that the data requirements of a client is determined by the API they connect to. GraphQL APIs are game changing because they allow the client to be completely flexible in deciding the type of data they actually require and typically only expose a single endpoint.
Some core concepts in GraphQL include:
-
Queries: This is the information sent to the server that describes the information the client needs.
-
Mutations: This is just like the query but they are used to perform action that requires data changing like updating, deleting and creating.
Other concepts include subscriptions, fragments, arguments and variables.
NuxtJS
Nuxt is based on a powerful modular architecture that can be used to build applications that are optimized out of the box while providing the best developer experience (from the NuxtJS website). This main buzz about NuxtJS is that it allows you build either spa or ssr apps easily, and this is very cool.
Installation
Let's set up our NuxtJS project. Run the following in your terminal:
yarn create nuxt-app <project-name>
Then:
cd <project-name>
Now let's run:
yarn dev
We should see our app running - (default localhost:3000).
Next, let's add the apollo plugin to our application:
yarn add @nuxtjs/apollo
Let’s import the @nuxtjs/apollo into our nuxt.config.js file:
modules: [
["@nuxtjs/apollo"]
]
Adding Apollo Configuration
Next, let's set up our apollo configuration inside the nuxt.config.js file.
apollo: {
tokenName: "nuxt-apollo", // specify token name
cookieAttributes: {
expires: 7 // optional, default: 7 (days)
},
defaultOptions: {
$query: {
fetchPolicy: "network-only",
errorPolicy: "all"
}
},
watchLoading: "@/apollo/loadingHandler.js",
errorHandler: "@/apollo/errorHandler.js",
clientConfigs: {
default: {
httpEndpoint: process.env.BASE_URL
}
}
},
-
tokenName: This is the cookie name if your app is browser based and you are using cookies for login and session management.
-
cookieAttributes: This holds the properties of the cookies you are saving to the users' browser. Expires: this is how long you want the cookies to be alive for.
-
defaultOptions: This holds properties you want to define globally for your apollo calls. An example is $query.
-
fetchPolicy: Depending on if you want to set up caching for your application, this can be used to specify which caching policy you want to use.
-
errorPolicy: This allows you to control how GraphQL errors from the server are sent to your UI code. By default, the error policy treats GraphQL errors as network errors and ends the request chain. errorPolicy can be set to none, ignore or all.
-
clientConfigs: It is used to configure endpoint, authentication and other parameters as well.
-
httpEndpoint: This is used to specify the GraphQL endpoint your app will use.
-
watchLoading(isLoading, countModifier) is a hook called when the loading state of the query changes. The countModifier parameter is either equal to 1 when the query is loading, or -1 when the query is no longer loading.
-
errorhandler(graphQLErrors, networkError, operation, forward) is a hook called when an error occurs.
Let's create a folder apollo then create loadingHandler.js and add it to our nuxt.config.js file:
export default (isLoading, countModifier) => {
console.log("Global loading handler");
console.log(isLoading, countModifier);
};
Let's create errorHandler.js. inside our apollo folder:
export default (
{ graphQLErrors, networkError, operation, forward },
nuxtContext
) => {
console.log("Global error handler");
console.log(graphQLErrors, networkError, operation, forward);
console.log(nuxtContext);
};
Making GraphQL Queries
Let's make a Query to pull users based on id.
First, create a fetchuser.gql file inside a query folder in apollo:
query user($id: ID!) {
user(id: $id) {
id
firstname
age
}
}
Inside Index.vue file, let’s import fetchuser.gql
import usersGql from "~/apollo/queries/fetchuser.gql";
Now, let's make our first query to pull users and specify prefecth as true.
prefetch is either a boolean or a function that helps determine if the query should be prefetched (fetched before mount). Using prefetch as true is a great way to use ssr to improve SEO.
apollo: {
user: {
prefetch: true,
query: usersGql,
variables() {
return { id: 1 };
},
update(data) {
return data.user;
},
},
}
We can call user inside template to see the user information.
<template>
<div class="container">
<div>
<h4 class="title">{{ user }}</h4>
</div>
</div>
</template>
Let's set prefetch as false, then show the status of the process using “$apollo.queries.user.loading” where user is the name of the query.
<template>
<div class="container">
<div>
<h4 class="title">
<template v-if="$apollo.queries.user.loading">I am still loading</template>
<template v-else>{{ user }}</template>
</h4>
</div>
</div>
Let’s try making use of nuxtServerInit to make a GraphQL query.
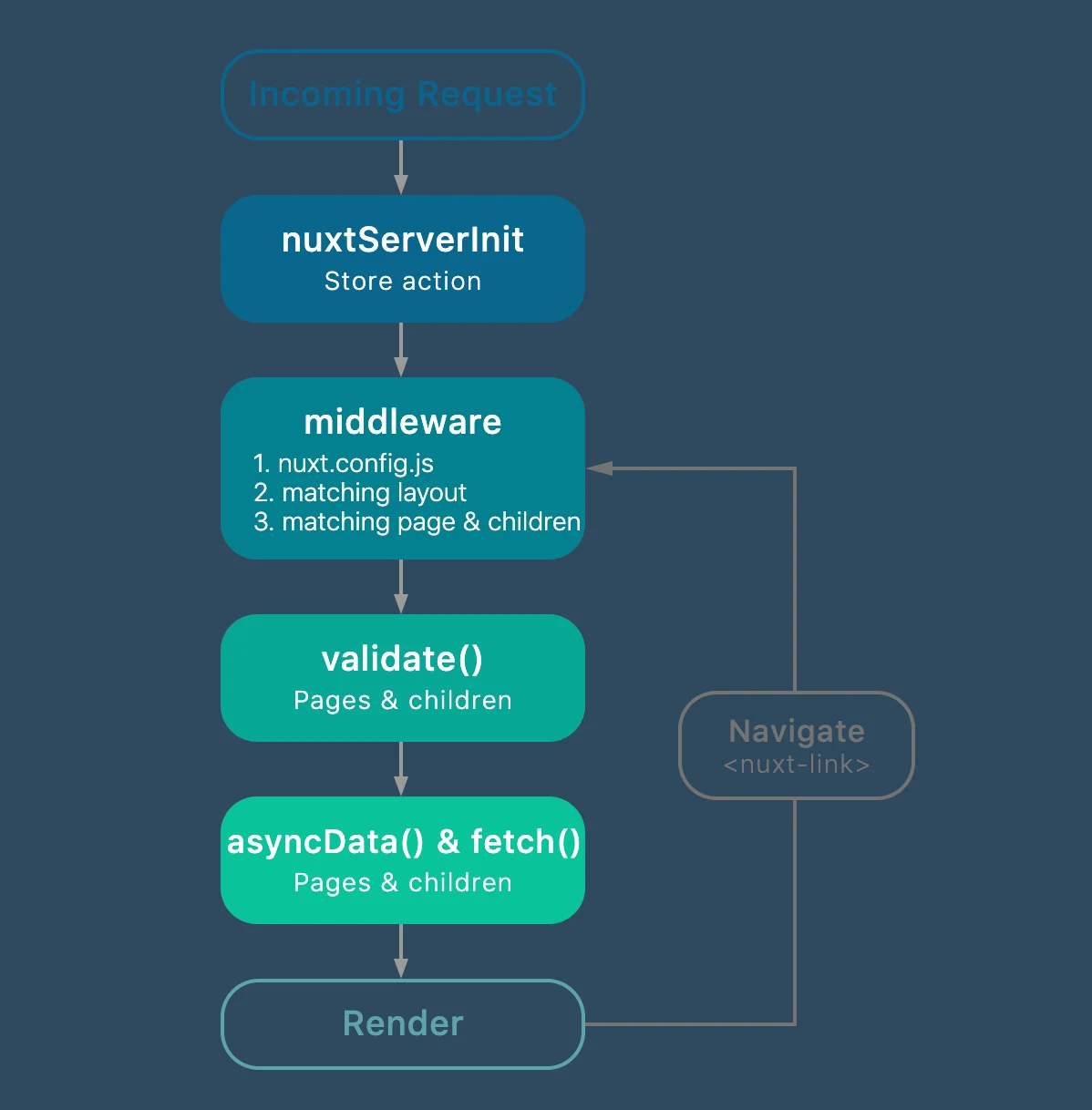
According to the official NuxtJS Website:
If the action nuxtServerInit is defined in the store and the mode is universal, Nuxt.js will call it with the context (only from the server-side). It's useful when we have some data on the server we want to give directly to the client-side.
Let’s import fetchuser.gql inside store (index.js)
import get_user_query from "~/apollo/queries/fetchusers.gql";
Then we make our query in nuxtServerInit:
export const state = () => ({
user: {}
});
export const mutations = {
set_user: function(state, user) {
state.user = user;
}
};
nuxtServerInit({ commit }, { error }) {
const clientApollo = this.app.apolloProvider.defaultClient;
return new Promise((resolve, reject) => {
clientApollo
.query({
query: get_user_query,
variables: {
id: 3
}
})
.then(resp => {
commit("set_user", resp.data.user);
resolve(resp);
})
.catch(err => {
resolve(err);
});
});
}
Now let's make use of the user data on our page:
import { mapState } from "vuex";
export default {
data() {
return {
};
},
computed: {
...mapState({
user: (state) => state.user
}),
},
}
<template>
<div class="container">
<div>
<h4 class="title">{{ user }}</h4>
</div>
</div>
</template>
Yay! I hope you now understand how to make GraphQL queries in NuxtJS. You can explore more advanced features like saving cookies when the user logs in and using nuxtServerInit to check for a user session. If you have any questions or run into any trouble, feel free to reach out on Twitter or Github.




