
Mastering Git Rerere: Solving Repetitive Merge Conflicts with Ease
Introduction:
Git, the popular version control system, has revolutionized how developers collaborate on projects. However, one common pain point in Git is repetitive merge conflicts. Fortunately, Git provides a powerful and not-so-well-known solution called git rerere (reuse recorded resolution) that can save you time and effort when resolving conflicts. In this blog post, we will explore how to configure and use git rerere, and demonstrate its effectiveness in solving merge conflicts.
Understanding Git Rerere:
Git rerere is a feature that allows Git to remember how you resolved a particular merge conflict in a particular file and automatically apply the same resolution in the future. It works by recording the conflict resolution in a hidden directory called .git/rr-cache. This way, when Git encounters the same conflict in the same file in the future, it can reuse the recorded resolution, saving you from manually resolving the conflict again.
Configuring Git Rerere:
Before using git rerere, you need to enable it in your Git configuration; only once git rerere has been enabled, Git will start recording and remembering resolved conflicts.Open your terminal and run the following command:
git config --global rerere.enabled true
This command enables git rerere globally, making it available for all your repositories. You can also enable it per-repository by omitting the --global flag.
How to use it:
Let's start with a really easy example, then describe a couple of use cases.
We have merged a branch (branch-one) into our main, and we are working on two different features in two different branches (branch-two and branch-three). We need to rebase our branches with main, so we start with
git checkout branch-two
git rebase main
It turns out that there are some conflicts on App.tsx file:
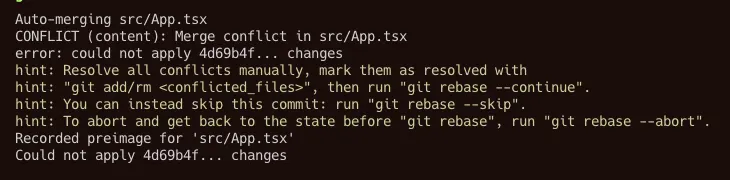
We solve all the conflicts and finish with the rebase and push. As you can see, there are an extra line in the rebase output message that says:
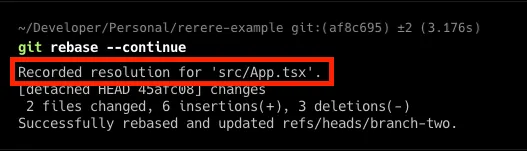
This means that thanks to rerere option enabled, we have saved in our project's .git/rr-cache this resolution for this particular conflict.
Now let's switch branches into branch-three cause we want to rebase on main also this one:
git checkout branch-three
git rebase main
It seems that we have the same conflicts here too, but this time, on the rebase output message, we can read:
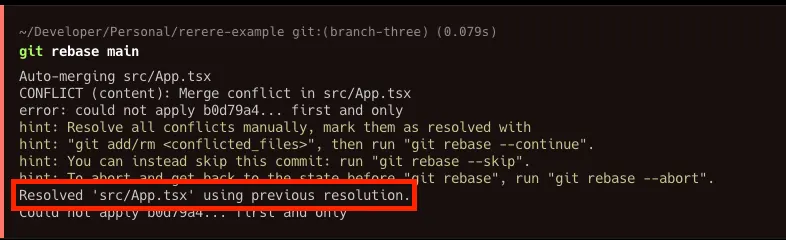
The conflict has been resolved automatically; if we check our IDE, we can see the change (and check if it works for us) ready to be committed and pushed with the same resolution we manually used in the past rebase.

The example above focuses on a rebase, but of course, git rerere also works for conflicts that came out from a merge command.
Here are a couple of real-life scenarios where git rerere can save the day:
Frequent Integration of Feature Branches: Imagine you're working on a feature branch that frequently needs to be merged into the main development branch. Each time you merge, you encounter the same merge conflicts. With git rerere, you only need to resolve these conflicts once. After that, Git remembers the resolutions and automatically applies them in future merges, saving you from resolving the same conflicts repeatedly.
Reapplying Patches or Fixes: Let's say you have a situation where you need to apply the same set of changes or fixes to multiple branches. When you encounter conflicts during this process, git rerere can remember how you resolved them the first time. Then, when you apply the changes to other branches, Git can automatically reuse the recorded resolutions, sparing you from manually resolving the same conflicts repeatedly.
Benefits of Git Rerere:
Git rerere offers several benefits that make it a valuable tool for developers, regardless of whether you prefer git merge or git rebase:
-
Time-saving: By reusing recorded resolutions, git rerere eliminates the need to manually resolve repetitive merge conflicts, saving you valuable time and effort.
-
Consistency: Git rerere ensures consistent conflict resolutions across multiple merges or rebases, reducing the chances of introducing errors or inconsistencies.
-
Improved productivity: With git rerere, you can focus on more critical tasks instead of getting stuck in repetitive conflict resolutions.
Conclusion:
Git rerere is a powerful feature that simplifies resolving repetitive merge conflicts. By enabling git rerere and recording conflict resolutions, you can save time, improve productivity, and ensure consistent conflict resolutions across your projects. Incorporate git rerere into your Git workflow, and say goodbye to the frustration of repetitive merge conflicts.




