Intro
Today’s article, will give a brief overview of the Architect framework and how to deploy a Remix app. I’ll cover a few different topics, such as what Architect is, why it’s good to use, and the issues I ran into while using it. It is a straightforward process, and I recommend using it with the Grunge Stack offered by Remix. So let’s jump on in and start talking about Architect.
Prerequisites
There are a few prerequisites and also some basic understandings that are expected going into this. The first is to have a GitHub account, then an AWS account, and finally some basic understanding of how to deploy. I also recommend checking out the Grunge Stack here if you run into any issues when we progress further.
What is Architect?
First off, Architect is a simple framework for Functional Web Apps (FWAs) on AWS. Now you might be wondering, "why Architect?" It offers the best developer experience, works locally, has infrastructure as code, is secured to the least privilege by default, and is open-source.
Architect prioritizes speed, smart configurable defaults, and flexible infrastructure. It also allows users to test things and debug locally. It defines a high-level manifest, and turns a complex cloud infrastructure into a build artifact. It complies the manifest into AWS CloudFormation and deploys it. Since it’s open-source, Architect prioritizes a regular release schedule, and backwards compatibility.
Remix deployment
Deploying Remix with Architect is rather straightforward, and I recommend using the Grunge Stack to do it. First, we’re going to head on over to the terminal and run npx create-remix --template remix-run/grunge-stack. That will get you a Remix template with almost everything you need.
Generating remix template
For the next couple of steps, you need to add your AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY to your repo’s secrets. You’ll need to create the secrets on your AWS account, and then add them to your repo.
AWS secrets
GitHub secrets
The last steps before deploying include giving CloudFormation a SESSION_SECRET of its own for both staging and production environments. Then you need to add an ARC_APP_SECRET.
Adding env variables
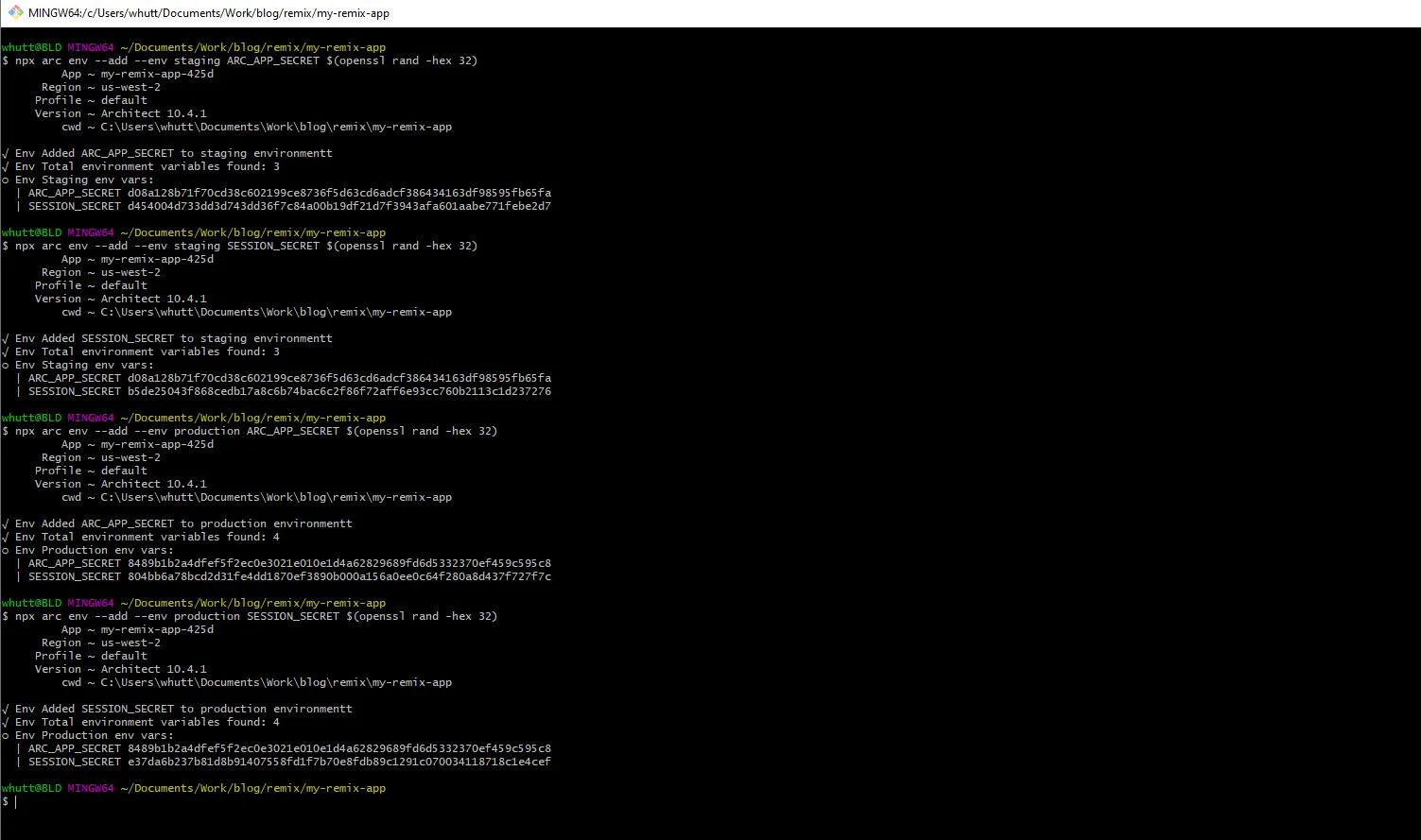
npx arc env --add --env staging ARC_APP_SECRET $(openssl rand -hex 32)
npx arc env --add --env staging SESSION_SECRET $(openssl rand -hex 32)
npx arc env --add --env production ARC_APP_SECRET $(openssl rand -hex 32)
npx arc env --add --env production SESSION_SECRET $(openssl rand -hex 32)
With all of that out of the way, you need to run npx arc deploy, which will deploy your build to the staging environment. You could also do npx arc deploy —-dry-run beforehand to verify everything is fine.
Issues I Had in My Own Project
Now let's cover some issues I had, and my solution for my own project. So, I had a project far into development, and while looking at the Grunge Stack, I was scratching my head, trying to figure out what was necessary to bring over to my existing project.
I had several instances of trial and error as I plugged in the Architect related items. For instance: the arc file, which has the app name, HTTP routes, static assets for S3 buckets, and the AWS configuration. I also had to change things like the remix.config file, adding a server.ts file, and adding Architect related dependencies in the package.json.
During this process, I would get errors about missing files or missing certain function dirs(), and I dumped a good chunk of time into it. So while continuing to get those errors, I concluded that I would follow the Grunge Stack, and their instructions for a new project. Then I would merge my old project with the new project; and that resolved my issues. While not the best way, it did get me going, and did not waste any more time.
That resolved my immediate issues of trying to get my Remix app deployed to AWS, but then I had to figure out what got pushed. That was easy, since it created a lambda, API gateway, and bucket based on the items in my arc file. Then I realized, while testing it out live, that my environmental variables hadn’t carried over, so I had to tweak those on AWS. My project also used a GitHub OAuth app. So that needed to be tweaked with the new URL. Then it was up and running.
Conclusion
Today’s article covered a brief overview of what Architect is, why it’s good to use, how to deploy a Remix app and the issues you might have. I hope it was useful and will give others a good starting point.




