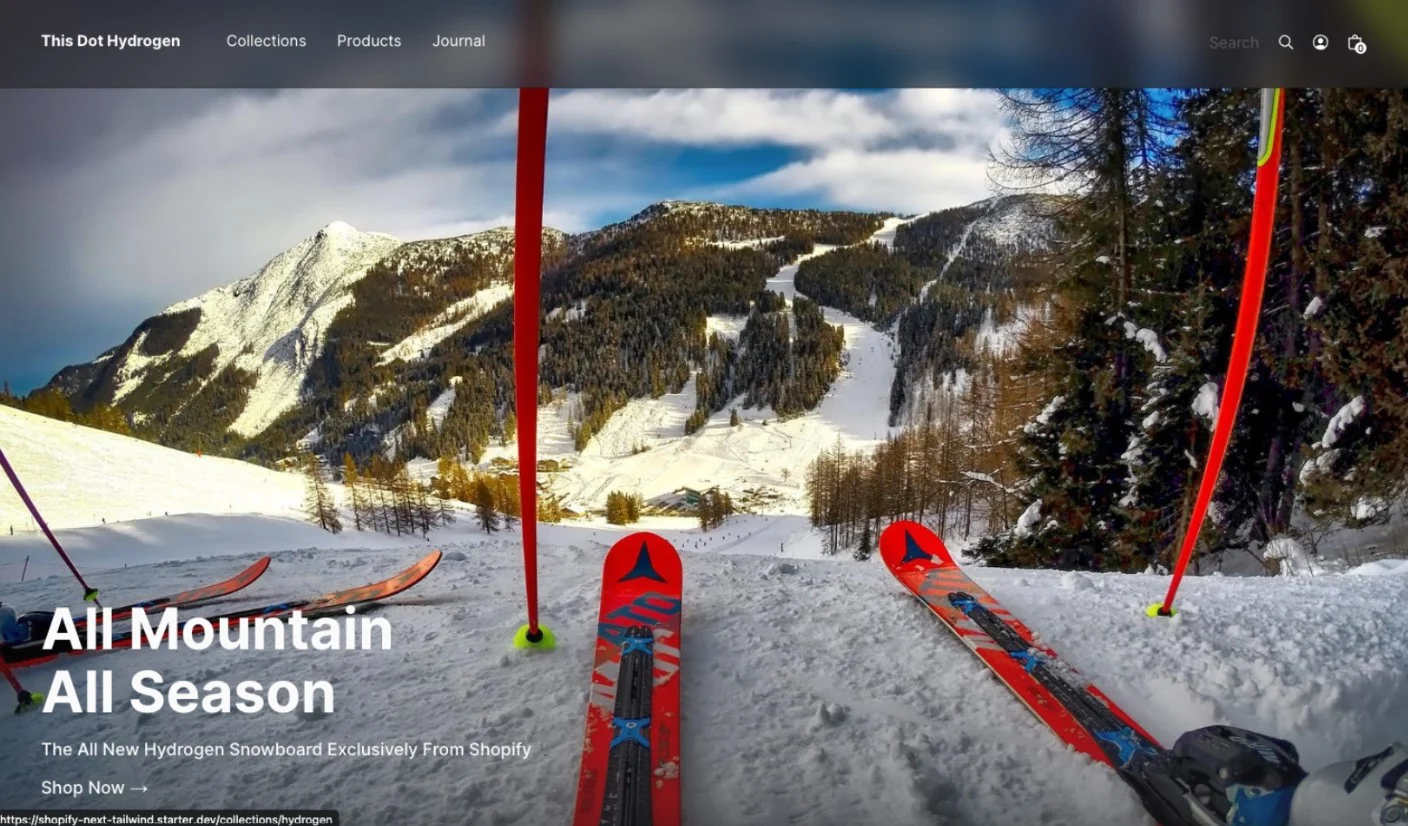
Intro
We are delighted to announce our brand new Shopify and Next.js 13 starter kit to our Starter.dev kits collection. This Starter kit is amazing to help you and your team quickly bootstrap a custom Shopify storefronts powered by Next.js 13 App Router since it has almost every feature you need for production set up and running!
Why did we build it?
At This Dot Labs, we work with a variety of clients, from big corporations to startups. Recently, we realized that we have a lot of clients who use Shopify that want to build custom stores using Next.js to benefit from its features. Additionally, we know that Hydrogen Shopify has only been limited to Remix since they acquired it. We had a lot of a hard time refilling the gap Hydrogen left to implement its features from scratch in our client projects. And from here, we realized that we need to build a starter kit to:
- Help our teams build custom storefronts using Next.js Quickly
- Reduce the cost for our clients
There were a lot of Next.js Shopify starters out there, but they were very basic and didn’t have all the features our teams needed, unlike the Official Hydrogen Starter Example which is complete. So, we decided to convert the Hydrogen starter from Remix/Hydrogen to Next.js, and use the power of the App Router and React Server Components.
Tech Stack
We used in this project:
Why Shopify
Shopify is a great e-commerce platform. They have a lot of experience in this field since 2006, and now over 4.12 million e-commerce sites are built with Shopify. (Source: Builtwith.com.) Shopify is used by online sellers in over 175 countries around the world, with 63% of Shopify stores estimated to be based in the US.
Why Next.js 13
As we mentioned above, we have a lot of clients who already use Next.js and it’s a very popular framework in the market for its flexibility, scalability, and diverse collection of features.
Features
Since this starter kit is based on the official Shopify Hydrogen template, it has all of it’s features as well including:
- Light/Dark themes support
- Authentication system with login, register, forgot password, and account pages
- Supports both Mobile/Desktop screens
- Has built-in infinity scroll pagination, built with Server Components
- State management using Zustand
- Variety of custom fonts
- All components have been built with Tailwind
- Static analysis testing tools pre-configured like TypeScript, Eslint, Prettier, and a lot of useful extensions
- Storybooks for the consistency of the system design
- GitHub Pull requests and release templates
- Shopify analytics integrated with the kit
- Great performance and SEO scores
- And finally, incompatible performance tested by both Lighthouse and PerfBuddy
Performance
This kit is running at top performance! It has amazing performance, SEO, and accessibility scores.
We tested it using PerfBuddy, and the results are incredible on both Desktop and Mobile. Here is the full report.
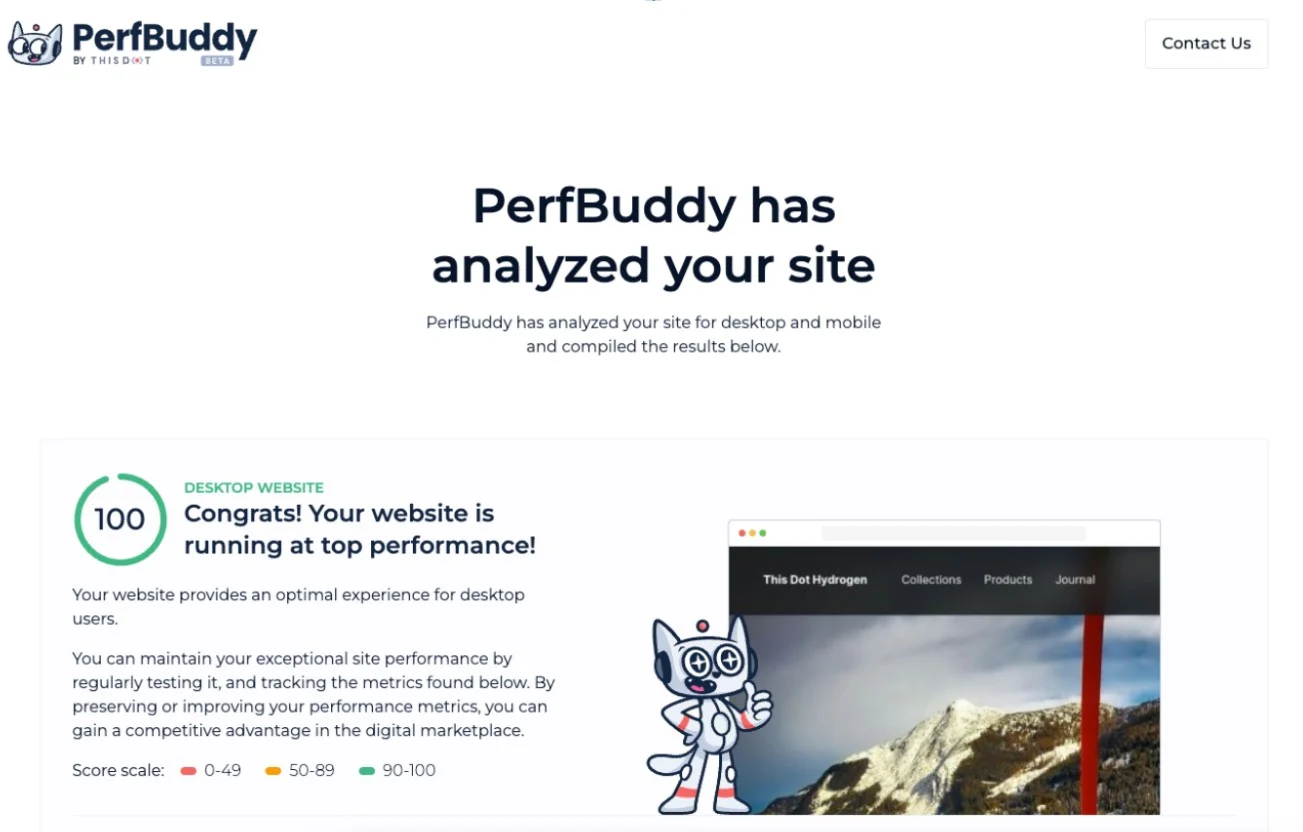
Note: PerfBuddy is an incredible free tool to analyze the performance of your web apps accurately. Check it out!
Also, the results from Lighthouse are pretty fascinating:

When do I use this kit?
This starter kit is great for starting new custom storefronts rapidly, especially for startups to save time and money. Also, it can be used to migrate from the old Next.js storefront to the new App router directory as it has all of the examples your team will need to integrate Shopify in Next.js 13
Conclusion
We are very excited to share this starter kit with you, and we hope you find it useful for your projects. We are looking forward to hearing your feedback and suggestions to improve it, and add more features to it. Also, we are planning to add more starter kits to our Starter.dev collection, so stay tuned for more updates!




