
Background
We recently engaged with a client reporting performance issues with their product. It was a legacy ASP .NET application using Entity Framework to connect to a Microsoft SQL Server database. As the title of this post and this information suggest, the misuse of this Object-Relational Mapping (ORM) tool led to these performance issues. Since our blog primarily focuses on JavaScript/TypeScript content, I will leverage TypeORM to share examples that communicate the issues we explored and their fixes, as they are common in most ORM tools.
Our Example Data
If you're unfamiliar with TypeORM I recommend reading their docs or our other posts on the subject. To give us a variety of data situations, we will leverage a classic e-commerce example using products, product variants, customers, orders, and order line items. Our data will be related as follows:
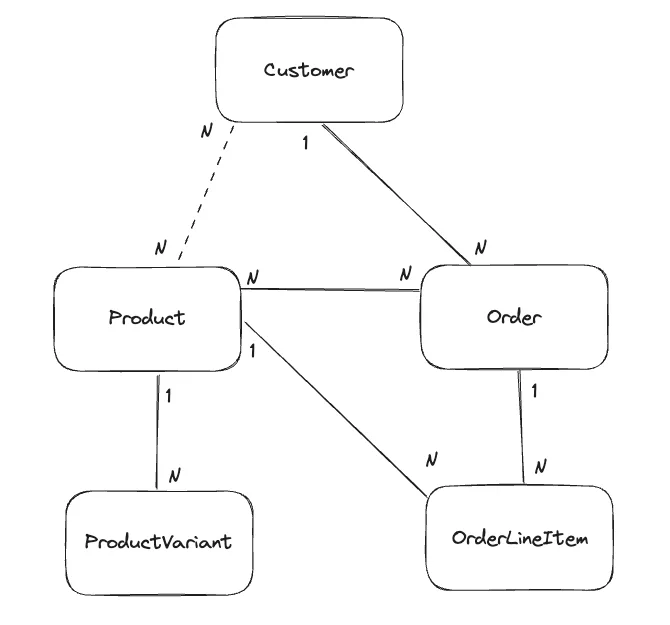
The relationship between customers and products is one we care about, but it is optional as it could be derived from customer->order->order line item->product. The TypeORM entity code would look as follows:
import { Entity, PrimaryGeneratedColumn, Column, OneToMany, ManyToOne, JoinColumn } from 'typeorm';
@Entity()
export class Product {
@PrimaryGeneratedColumn()
id: number;
@Column()
name: string;
@Column({ type: 'text' }) // Use 'text' type for potentially long descriptions
description: string;
@OneToMany(() => ProductVariant, (variant) => variant.product)
variants: ProductVariant[];
@OneToMany(() => OrderLineItem, (item) => item.product)
lineItems: OrderLineItem[];
}
@Entity()
export class ProductVariant {
@PrimaryGeneratedColumn()
id: number;
@Column()
name: string;
@Column()
price: number;
@ManyToOne(() => Product, (product) => product.variants)
@JoinColumn() // Specifies the foreign key column
product: Product;
}
@Entity()
export class Customer {
@PrimaryGeneratedColumn()
id: number;
@Column()
name: string;
@OneToMany(() => Order, (order) => order.customer)
orders: Order[];
}
@Entity()
export class Order {
@PrimaryGeneratedColumn()
id: number;
@Column()
orderDate: Date;
@Column()
amount: number;
@ManyToOne(() => Customer, (customer) => customer.orders)
@JoinColumn()
customer: Customer;
@OneToMany(() => OrderLineItem, (item) => item.order)
items: OrderLineItem[];
}
@Entity()
export class OrderLineItem {
@PrimaryGeneratedColumn()
id: number;
@Column()
quantity: number;
@ManyToOne(() => Product, (product) => product.lineItems)
@JoinColumn()
product: Product;
@ManyToOne(() => Order, (order) => order.items)
@JoinColumn()
order: Order;
}
With this example set, let's explore some common misuse patterns and how to fix them.
N + 1 Queries
One of ORMs' superpowers is quick access to associated records. For example, we want to get a product and its variants. We have 2 options for writing this operation. The first is to join the table at query time, such as:
import { getRepository } from 'typeorm';
async function getProductWithVariants(productId: number) {
const productRepository = getRepository(Product);
const product = await productRepository.findOne({
where: { id: productId },
relations: ['variants'] // Eagerly load variants via join
});
if (product) {
return product; // The product object now includes its variants
} else {
throw new Error('Product not found');
}
}
Which resolves to a SQL statement like (mileage varies with the ORM you use):
SELECT *
FROM Product as p, ProductVariant as pv
WHERE p.id = productId
AND p.id = pv.productId;
The other option is to query the product variants separately, such as:
import { getRepository } from 'typeorm';
async function getProductWithVariants(productId: number) {
const productRepository = getRepository(Product);
const productVariantRepository = getRepository(ProductVariant);
const product = await productRepository.findOne({ where: { id: productId } });
if (product) {
const variants = await productVariantRepository.find({
where: { product: { id: productId } }
});
return { …product, variants };
} else {
throw new Error('Product not found');
}
}
This example executes 2 queries. The join operation performs 1 round trip to the database at ~200ms, whereas the two operations option performs 2 round trips at ~100ms. Depending on the location of your database to your server, the round trip time will impact your decision here on which to use. In this example, the decision to join or not is relatively unimportant and you can implement caching to make this even faster. But let's imagine a different situation/query that we want to run. Let's say we want to fetch a set of orders for a customer and all their order items and the products associated with them. With our ORM, we may want to write the following:
import { getRepository } from 'typeorm';
async function fetchCustomerOrdersWithDetails(customerId: number) {
const orderRepository = getRepository(Order);
const orderItemRepository = getRepository(OrderItem);
const productRepository = getRepository(Product);
const orders = await orderRepository.find({
where: { customer: { id: customerId } }
});
for (const order of orders) {
const orderItem = await orderItemRepository.findOne(order);
order.items.push(orderItem);
for (const item of order.items) {
const product = await productRepository.findOne(item.product);
item.product = product;
}
}
return orders; // All orders with items and products populated
}
When written out like this and with our new knowledge of query times, we can see that we'll have the following performance: 100ms * 1 query for orders + 100ms * order items count + 100ms * order items' products count. In the best case, this only takes 100ms, but in the worst case, we're talking about seconds to process all the data. That's an O(1 + N + M) operation! We can eagerly fetch with joins or collection queries based on our entity keys, and our query performance becomes closer to 100ms for orders + 100ms for order line items join + 100ms for product join. In the worst case, we're looking at 300ms or O(1)!
Normally, N+1 queries like this aren't so obvious as they're split into multiple helper functions. In other languages' ORMs, some accessors look like property lookups, e.g. order.orderItems. This can be achieved with TypeORM using their lazy loading feature (more below), but we don't recommend this behavior by default. Also, you need to be wary of whether your ORM can be utilized through a template/view that may be looping over entities and fetching related records. In general, if you see a record being looped over and are experiencing slowness, you should verify if you've prefetched the data to avoid N+1 operations, as they can be a major bottleneck for performance. Our above example can be optimized by doing the following:
async function fetchCustomerOrdersWithDetails(customerId: number) {
const orderRepository = getRepository(Order);
const orderItemRepository = getRepository(OrderItem);
const productRepository = getRepository(Product);
const orders = await orderRepository.find({
where: { customer: { id: customerId } }
});
const orderItems = await orderItemRepository.find({
where: orders.map(order => ({ order: { id: order.id } }))
});
const products = await productRepository.find({
where: orderItems.map(orderItem => ({ id: orderItem.product.id }))
});
const orderItemsByOrder = groupBy(orderItems, 'orderId');
const productsById = indexBy(products, 'id');
for (const order of orders) {
order.items = orderItemsByOrder[order.id];
for (const item of order.items) {
item.product = productsById[item.productId];
}
}
return orders;
}
function indexBy(arr, key) {
return arr.reduce((acc, item) => {
acc[item[key]] = item;
return acc;
}, {});
}
function groupBy(arr, key) {
return arr.reduce((acc, item) => {
if (!acc[item[key]]) {
acc[item[key]] = [];
}
acc[item[key]].push(item);
return acc;
}, {});
}
Here, we prefetch all the needed order items and products and then index them in a hash table/dictionary to look them up during our loops. This keeps our code with the same readability but improves the performance, as in-memory lookups are constant time and nearly instantaneous. For performance comparison, we'd need to compare it to doing the full operation in the database, but this removes the egregious N+1 operations.
Eager v Lazy Loading
Another ORM feature to be aware of is eager loading and lazy loading. This implementation varies greatly in different languages and ORMs, so please reference your tool's documentation to confirm its behavior. TypeORM's eager v lazy loading works as follows:
- If eager loading is enabled for a field when you fetch a record, the relationship will automatically preload in memory.
- If lazy loading is enabled, the relationship is not available by default, and you need to request it via a key accessor that executes a promise.
- If neither is enabled, it defaults to the behavior ascribed above when we explained handling N+1 queries.
Sometimes, you don't want these relationships to be preloaded as you don't use the data. This behavior should not be used unless you have a set of relations that are always loaded together. In our example, products likely will always need product variants loaded, so this is a safe eager load, but eager loading order items on orders wouldn't always be used and can be expensive.
You also need to be aware of the nuances of your ORM. With our original problem, we had an operation that looked like product.productVariants.insert({ … }). If you read more on Entity Framework's handling of eager v lazy loading, you'll learn that in this example, the product variants for the product are loaded into memory first and then the insert into the database happens. Loading the product variants into memory is unnecessary. A product with 100s (if not 1000s) of variants can get especially expensive. This was the biggest offender in our client's code base, so flipping the query to include the ID in the insert operation and bypassing the relationship saved us seconds in performance.
Database Field Performance Issues
Another issue in the project was loading records with certain data types in fields. Specifically, the text type. The text type can be used to store arbitrarily long strings like blog post content or JSON blobs in the absence of a JSON type. Most databases use a technique that stores text fields off rows, which requires a special file system lookup operation to fetch that data. This can make a typical database lookup that would take ~100ms under normal conditions to take ~200ms. If you combine this problem with some of the N+1 and eager loading problems we've mentioned, this can lead to seconds, if not minutes, of query slowdown. For these, you should consider not including the column by default as part of your ORM.
TypeORM allows for this via their hidden columns feature. In this example, for our product description, we could change the definition to be:
@Entity()
export class Product {
// … omitted for brevity
@Column({ type: 'text', select: false })
description: string;
// … omitted for brevity
}
This would allow us to query products without descriptions quickly. If we needed to include the product description in an operation, we'd have to use the addSelect function to our query to include that data in our result like:
const product = await productRepository
.addSelect('product.description')
.findOne({
where: { id: productId },
});
This is an optimization you should be wary of making in existing systems but one worth considering to improve performance, especially for data reports. Alternatively, you could optimize a query using the select method to limit the fields returned to those you need.
Database v. In-Memory Fetching
Going back to one of our earlier examples, we wrote the following:
const orderItems = await orderItemRepository.find({
where: orders.map(order => ({ order: { id: order.id } }))
});
const orderItemsByOrder = groupBy(orderItems, 'orderId');
This involves loading our data in memory and then using system memory to perform a group-by operation. Our database could have also returned this result grouped. We opted to perform this operation like this because it made fetching the order item IDs easier. This takes some performance challenges away from our database and puts the performance effort on our servers. Depending on your database and other system constraints, this is a trade-off, so do some benchmarking to confirm your best options here.
This example is not too bad, but let's say we wanted to get all the orders for a customer with an item that cost more than $20. Your first inclination might be to use your ORM to fetch all the orders and their items and then filter that operation in memory using JavaScript's filter method. In this case, you're loading data you don't need into memory. This is a time to leverage the database more. We could write this query as follows in SQL:
SELECT o.*
FROM Order as o, OrderLineItem li
WHERE o.customerId = customerId
AND o.id = li.orderId
AND li.amount > 20
This just loads the orders that had the data that matched our condition. We could write this as:
const orderRepository = getRepository(Order);
const orders = await orderRepository
.createQueryBuilder('o') // Alias for Order
.innerJoinAndSelect('o.items', 'li') // Join with OrderLineItem, alias 'li'
.where('o.customerId = :customerId', { customerId }) // Filter by customer ID
.andWhere('li.amount > 20') // Filter by item cost
.getMany();
We constrained this to a single customer, but if it were for a set of customers, it could be significantly faster than loading all the data into memory. If our server has memory limitations, this is a good concern to be aware of when optimizing for performance. We noticed a few instances on our client's implementation where the filter operations were applied in functions that appeared to run the operation in the database but were running the operation in memory, so this was preloading more data into memory than needed on a memory-constrained server. Refer to your ORM manual to avoid this type of performance hit.
Lack of Indexes
The final issue we encountered was a lack of indexes on key lookups. Some ORMs do not support defining indexes in code and are manually applied to databases. These tend not to be documented, so an out-of-sync issue can happen in different environments. To avoid this challenge, we prefer ORMs that support indexes in code like TypeORM. In our last example, we filtered on the cost of an order item, but the cost field does not contain an index. This leads to a full table scan of our data collection filtered by the customer. The query cost can be very expensive if a customer has thousands of orders. Adding the index can make our query super fast, but it comes at a cost. Each new index makes writing to the database slower and can exponentially increase the size of our database needs. You should only add indexes to fields that you are querying against regularly. Again, be sure you can notate these indexes in code so they can be replicated across environments easily.
In our client's system, the previous developer did not include indexes in the code, so we retroactively added the database indexes to the codebase. We recommend using your database's recommended tool for inspection to determine what indexes are in place and keep these systems in sync at all times.
Conclusion
ORMs can be an amazing tool to help you and your teams build applications quickly. However, they have gotchas for performance that you should be aware of and can identify while developing or during code reviews. These are some of the most common examples I could think of for best practices. When you hear the horror stories about ORMs, these are some of the challenges typically discussed. I'm sure there are more, though. What are some that you know? Let us know!




